
Stable Diffusion の環境を作る ~ 画像生成AI ①
生成AIをいろいろと試してみたいとHPのOMEN35Lを購入して、初期設定等を終えたところです。別途コストはかかりましたが、自宅内の別場所からリモートデスクトップで使用できるよう、Windows11 Proへのアップグレードを済ませています。

ローカルでの画像生成環境
で、今回から、少しずつ、生成AIの話に入っていきたいと思います。
何から始めようかと考えたんですが、まずは、やっぱり見た目のインパクトが大きい画像生成をやってみたいですよね。
そこで、最終的な目標を「このブログのナビゲーター的なキャラクター(仮想の人物)を作成する」というところに置いて、何回かにわたってのシリーズものの記事にしてみたいと思います。
現在では、クラウドでも画像生成を無料で利用できるサービスが多々あります。さすがに高性能なGPUが使用されているようで、手軽に高品質な画像を生成できるのは大きな魅力ですよね。
クラウド生成/ローカル生成に関わらず、画像生成は一発で思い通りの結果を出すのは難しいようで、画像完成までに試行錯誤を重ねることになります。無料のサービスだと、生成できる枚数への上限にかかったり、混雑状況によっては待ちの時間が発生したりと、気になる場面も出てくるかもしれませんね。
有料サービスを利用すると、待ち時間が減ったり上限枚数の制限が無くなったりする一方で試行錯誤が必要なことは変わらず、それに要した分も生成枚数にカウントされますので、求める画像生成への試行錯誤を楽しみたい、という場合には最終的な画像生成までの進め方を、あらかじめ意識しておく必要があるかもしれません。
コスト面に関してローカルでの環境は、もちろんPCという初期投資はそれなりに高額となりますが、ランニングコストはほぼ電気代だけですので、納得いくまで生成を試すことが出来るのでは?というところに期待しています。
性能(品質)面やコストなど、いろいろな尺度がありますのでどちらが良いという話ではなく、(ランニング)コストを気にせず試行錯誤を楽しみたいという点からローカルでの画像生成に魅力を感じていることもあり、ローカルでの画像生成を最初のテーマとしてみました。
実は、単純に「ローカルPCで画像生成を試す」だけなら、PCを新たに購入しなくとも、手持ちのOMEN25L(RTX 2060 Super:VRAM 8GB)でも可能です。むしろ、初期投資ゼロで最強のコストパフォーマンスだったんですが、VRAM容量や生成時間を考えると、もう一段余裕が欲しいと感じるようになってきたんですね。良くも悪くも、少し触れたからこそ「もう少し上位機種を」という欲求が高まったと言えます。で、最低でも16GBのVRAMを搭載した 5060 Ti、懐が許すなら性能に余裕が出る 5070 Tiを候補として、機種選定をしたわけです。
…ですので、画像生成は全くの初心者ではないのですが、今回のPC購入を機に、ゼロから構築の話を書いてみたいと思います。
環境構築の流れ
この回では、ほぼ購入時状態のWindows11 PCに Stable Diffusion という深層学習モデルを導入し、画像生成を行う環境を作るところまでを一気にやってみたいと思います。一部、ダウンロードにユーザー登録などが必要なところもありますが、それらを含めて全て無料で実施可能です。
以降、書いてあるままに進めると環境が出来るはずですが、ちょっと理解を深めておくと「なるほど」な部分があるので、簡単に整理してみたいと思います。
Stable Diffusion は、文章(プロンプト)を入力することで、AIが画像を生成する画像生成AIです。
とはいえ、「Stable Diffusion」という一つのソフトがあるわけではなく、Stable Diffusionは、「画像生成AIモデル」「画像を生成するプログラム」「操作用のUI」をまとめた総称、ということのようです。
今回は、利用実績の多い(らしい)、ごく一般的な構成での構築にしたいと思います。
| 操作用UI | AUTOMATIC1111 WebUI |
| 画像生成プログラム | PyTorch |
| 画像生成AIモデル | Stable Diffusion 1.5 (SD1.5) |
UIには、AUTOMATIC1111 WebUIと呼ばれるメジャーな実行環境を用います。
Stable Diffusionでの画像生成AIモデルには、SD1.5やSDXLなどの系統がありますが、まずは基本に忠実に、ということでSD1.5を使用することにします。
画像生成プログラムは、画像生成・学習・推論のロジックの中心部、エンジン部になりますが、現在はほぼPyTorch(パイトーチ)系で共通のようですね。
階層イメージとしてはこんな感じになるかと思います。
【ユーザー】
│ プロンプト入力・設定
▼
【操作用UI】
・AUTOMATIC1111 WebUI
・ComfyUI / InvokeAI など
│
▼
【画像生成プログラム】
・PyTorch
・diffusers
│
▼
【画像生成AIモデル】
・Stable Diffusion 1.5
・Stable Diffusion XL など
│
▼
【GPU実行基盤】
・CUDA(NVIDIA)
・ROCm(AMD)
・DirectML(Windows)
│
▼
【GPUハードウェア】
・NVIDIA / AMD / Intelこのイメージからもわかる通り、画像生成の演算はGPUで行います。ですので、GPU性能と、GPUに積まれるVRAM容量がモノを言う、ということになります。逆に、CPUとPCのメモリは大きな影響を与えないようです(もちろん、高性能/大容量の方が良いのは間違いないですけどね)。
GPUと画像生成プログラムの間を取り持っているのがGPU実行基盤…なんですが、NVIDIAのGPUなら演算にCUDA(クーダ)というものを使うそうだ…くらいの理解でいいんじゃないでしょうか。CUDAを利用するのはPyTorch等のソフトであって、我々ユーザーが直接使用することはありません。とはいえ、CUDA関連のエラーが出る可能性も多いため、どこに位置するものか(GPUとの結びつきが強い)、くらいは知っておいた方が良いかも、というところですね。
GPUの種類ごとの差異はGPU実行基盤で吸収されますので、Stable Diffusion自体は、NVIDIA製GPU用、AMD製GPU用等といった区別はありません。そのCUDAも単体でインストールする必要はなく、GPUドライバと一緒にインストールされますので、なおさら「気にしなれけば気にならない存在」なのかもしれませんね。
ですので、環境構築は、NVIDIAが提供するGPUドライバ(CUDA対応)をインストールするところから始めます。
その後、Stable Diffusionを取得するためのGitの導入、Pythonのインストール、WebUIをインストールの後、モデルを配置すると、画像が生成できる状態になる、という次第です。
では、実際にやっていきましょう。
GPUドライバの確認
OMEN35Lを購入した状態で、既にGPUドライバがインストールされているのではないかと思います。もし、最新でなければ、「NVIDIA App」で「Game Ready ドライバーの最新版」をインストールします。
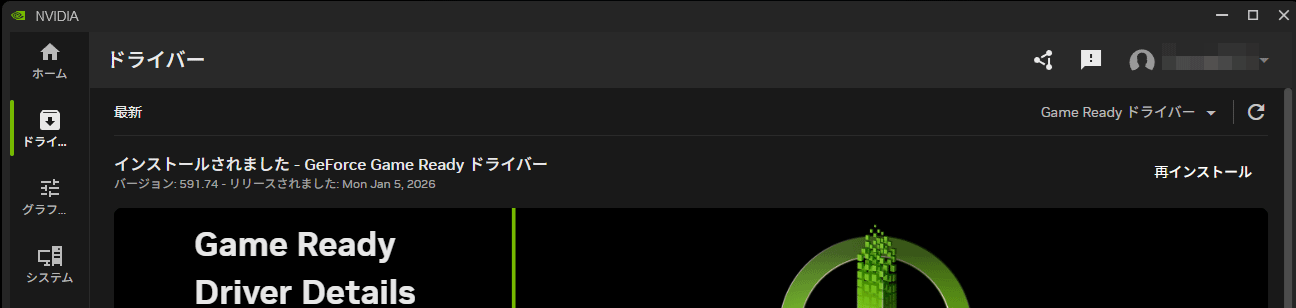
2026/1/24現在では、この「591.74」が最新でした。
というわけで、第1ステップは、この確認だけで終了です。
Git導入
SVNは使ったことがあるけど、Gitは…、という方もいらっしゃるかもしれませんが、ここでのGitは単にGitHubから環境を取得するためだけですので、難しく考える必要は無いかと思います。ユーザーの登録が必要ですが、これは以前から利用しているので、私はログインするだけだったんですが、初めての方は、登録から、になりますね。
https://git-scm.com を開き、「Install for Windows」からインストーラーをダウンロード。

ここは、特に最新にこだわる必要は無いと思いますので、導入済みの方はすっ飛ばしてください。
Git-2.52.0-64-bit.exe をダウンロードして、インストールしました。
セットアップウィザードに従って、何も設定を変えずにインストールしてます。
インストール後、バージョンの確認。
C:\Users\XXXX>git --version
git version 2.52.0.windows.1このようにバージョンが表示されればOKです。
Python 3.10のインストール
Pythonのバージョンは、3.10の安定版、3.10.11をインストールします。以前(ONEN25Lでの試用のとき)、何も考えずに導入当時の最新版(3.13)をインストールして、かなりはまりました。
Stable Diffusionは、3.10での使用が前提とされているそうで、3.11以上で発生する不具合は優先度を低く見られているのが実情のようですね。
2021年にリリースされた 3.10はサポート期限が2026年10月と、あと9ヶ月ほどなのですが、Stable Diffusion が 3.11以上で使えない、となるとこのバージョンを維持するしかないですよね。
もっとも、ローカル運用のための環境ですので外部に公開することもないでしょうし、すぐにセキュリティリスクが高まるということは無いかとは思います。
Stable Diffusionは、Pythonの仮想環境(venv)上で動きます。これは、他のPythonソフトと設定や依存関係を混在させないために有効な仕組みとなります。それに、Stable Diffusionが想定しているPythonのバージョン(3.10)をその環境内で固定できる、という点でも役立ちます。
とはいえ、venvを難しく考える必要はありません。コマンドを実行するときに、「いま仮想環境の中にいるのか、外にいるのか」を意識する程度で十分です。後で説明するインストール手順ではそのあたりも自動的に処理されます。
https://www.python.org から、[ダウンロード]タブ > [Windows]へと進みます。
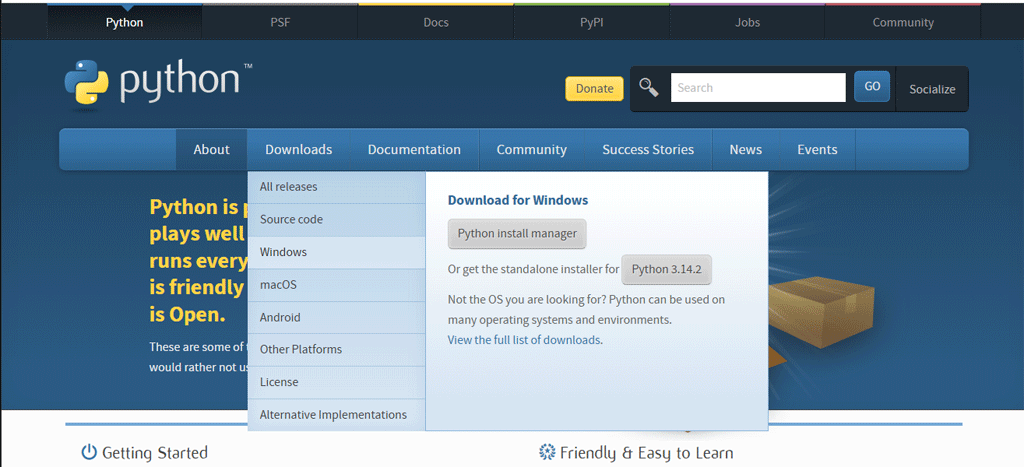
遷移した先で、上部には最新に近いバージョンが並んでいますが、スクロールして、Ptython 3.10 としての最新版、Python 3.10.11 – April5, 2023 の Windows installer(64-bit)をダウンロードしてインストールします。
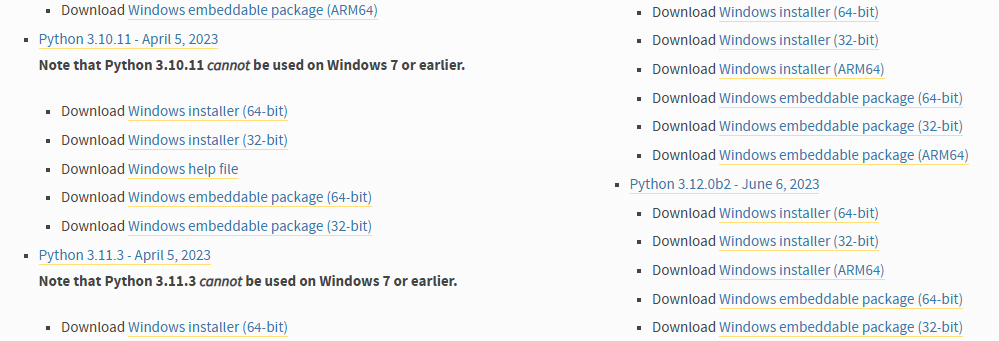
こちらもインストールウィザードで問題なく完了しますが、最初の画面の最下段「Add python.exe to PATH」にチェックを入れておくと、後がスムーズです。環境変数へのパスの設定ですね。
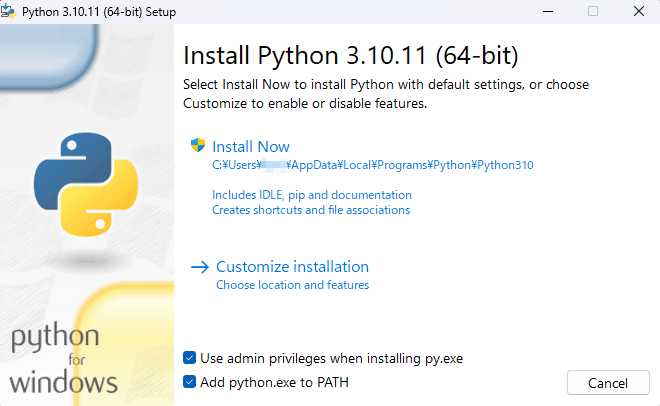
こちらもインストール後に、バージョンの確認をやっておきます。
C:\Users\XXXX>python --version
Python 3.10.11とバージョンが表示されればOKです。
Stable Diffusion WebUI の導入
実行環境を配置するフォルダを作成します。
わかりやすく、 C:\AI なんかがいいんじゃないでしょうか。
で、そこでターミナルを開いて、
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.gitとしてGitHubから環境を取得します。どこかのサイトでインストーラーを入手する、というようなものではありません。
上記の通り環境をごっそりと取得すればOK(完了)、だと思っていたんですが、RTX 5070 Ti だと、これだけではNGなようです。
試行錯誤したことを記録として残してもいいんですが、ちょっと遠回りになるので、まずは、いきなり解決法を。
上記の clone で問題なく取得まではできるのですが、AUTOMATIC1111 の初回起動時に取得するGitHubのリポジトリが無くなっているようで、Stability-AI/stablediffusion.git が見つからない、とエラーになって終了します。ですので、別リポジトリを参照するdevブランチに切り替えます。
cd stable-diffusion-webui
git switch dev
git pull次いで、C:\AI\stable-diffusion-webui\ に生成されている、webui-user.bat を修正します。前半部 set COMMANDLINE_ARGS=の下(call webui.bat より上)に次の行を追加します。
set TORCH_COMMAND=pip install --pre torch torchvision --index-url https://download.pytorch.org/whl/nightly/cu128これは、標準で導入されるPyTorchが 5070 Ti に未対応なので、CUDA 12.8(cu128)に対応したPyTorchを使用するための記述になります。
batファイルに追記せず、コマンドラインでインストール(pip install ~)も試したのですが、その後にbatを実行すると、再び古いtorchが使用されてしまうため、batファイルに書くことでcu128となるよう強制しています。
このように、実は、次項の生成モデルの取得を行った後、AUTOMATIC1111の実行段階でエラーが立て続けに発生して、いろいろと試した結果を反映したのが上記の修正となります。わざわざ同じように回り道をする必要はありませんからね。事前に対処しておいた方が良いと思います。
生成モデルの取得
続いては、画像生成の肝、画像生成AIモデルの入手です。
今回は、素のSD1.5モデルを使用してみたいと考えていますので、Hugging Face(ハギング・フェイス)社のサイトから取得します。
こちらも、すみません、アカウント取得済みなので登録についての記載は出来ないのですが、ゆるい公式マスコット(ロゴ)とは対照的な(…というと失礼ですが)、技術志向の強い硬派な会社ですので、安心して登録して頂ければ良いと思います。
ここで取得するのが、SD1.5系のベースとされる、v1-5-pruned-emaonly.safetensors です。
名前を解読すると、
v1-5
→ Stable Diffusion 1.5
pruned
→ 不要な重みを削除(軽量・安定)
emaonly
→ EMA重みのみ(推論・学習向き)
safetensors
→ 安全な形式ということで、SD1.5系では定番ファイルだそうです。
https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5 にアクセスします。
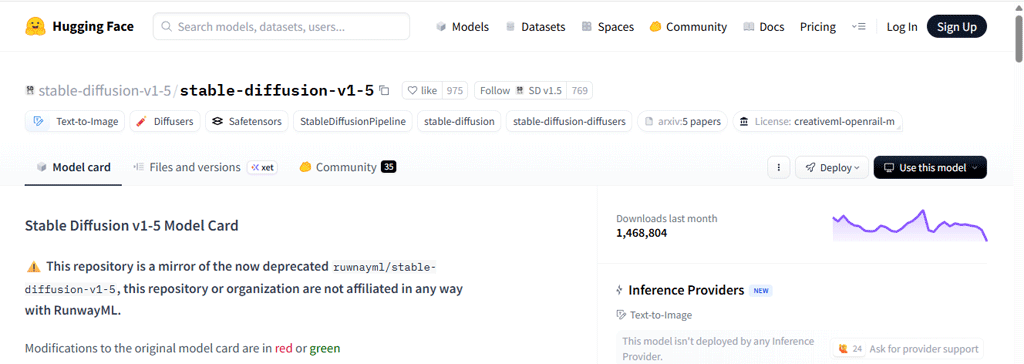
タブ(上記画面で表示中なのは[Model card])を、その隣の[Files and versions]に移動します。
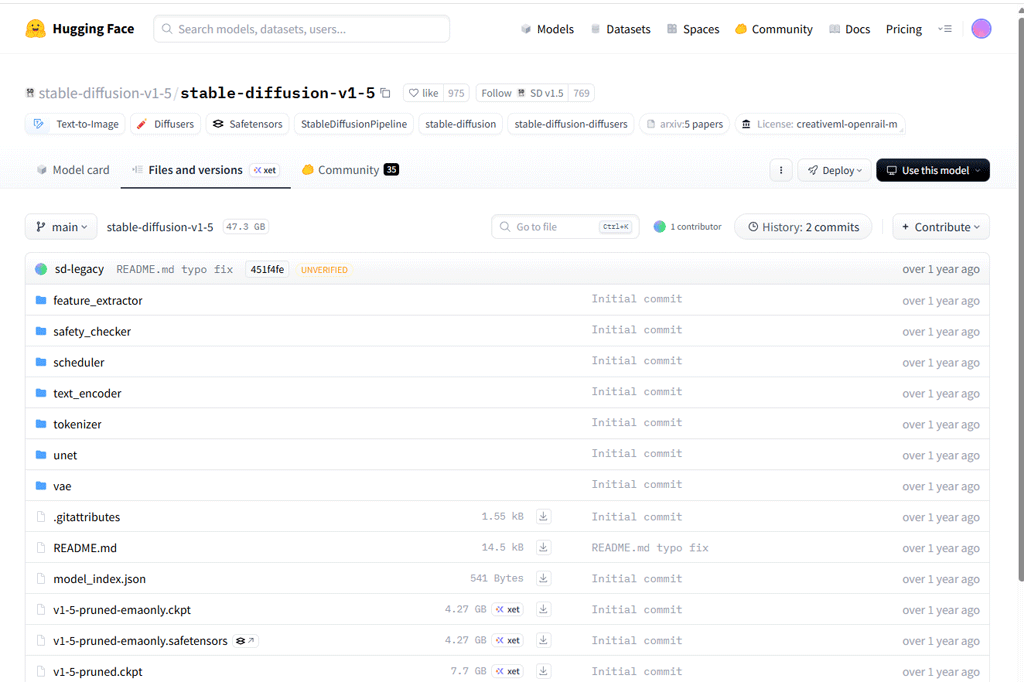
ファイル一覧の中に、(上記画面では下の方に) v1-5-pruned-emaonly.safetensors がありますので、その行の右側(中ほど)にあるダウンロードアイコン[↓]をクリックしてダウンロードします。
取得したファイルを、
stable-diffusion-webui
└─ models
└─ Stable-diffusion
└─ v1-5-pruned-emaonly.safetensorsに格納します。
なぜ、このファイルにこだわるのかというと、以降の回で画像生成での学習にもチャレンジしようと思ってますので、学習済みのモデルよりもピュアなモデルの方が何かと好都合だろう、という判断です。
ちなみに、画像生成AIモデルは Civitai で取得する、という話もよく耳にします。こちらでは、いろいろなチューニングが施された、目的に合った画像を生成しやすいモデルを配布している、というイメージになるでしょうか。なので、簡単に(完成に近い)画像を生成したい、という場合は、これらの利用も良い(むしろ近道)かと思います。
今回は、あくまでも「基本に忠実に」というところで、ピュアなモデルを使用することにしています。
いよいよ生成
ここまでで、導入の完了です。いくつかの手順を踏む必要はありましたが、それほどハードルが高かったわけではないと思います。
というわけで、C:\AI\stable-diffusion-webui\ にある webui-user.bat を叩きます。

初回は、いくつかのダウンロード(GitHubからの取得)があったりして時間がかかりますが、問題が無ければ、ブラウザに、AUTOMATIC1111の画面が表示されると思います。
途中で GitHub への Sign in を求められることがあるかと思いますので、適宜サインインしてください。
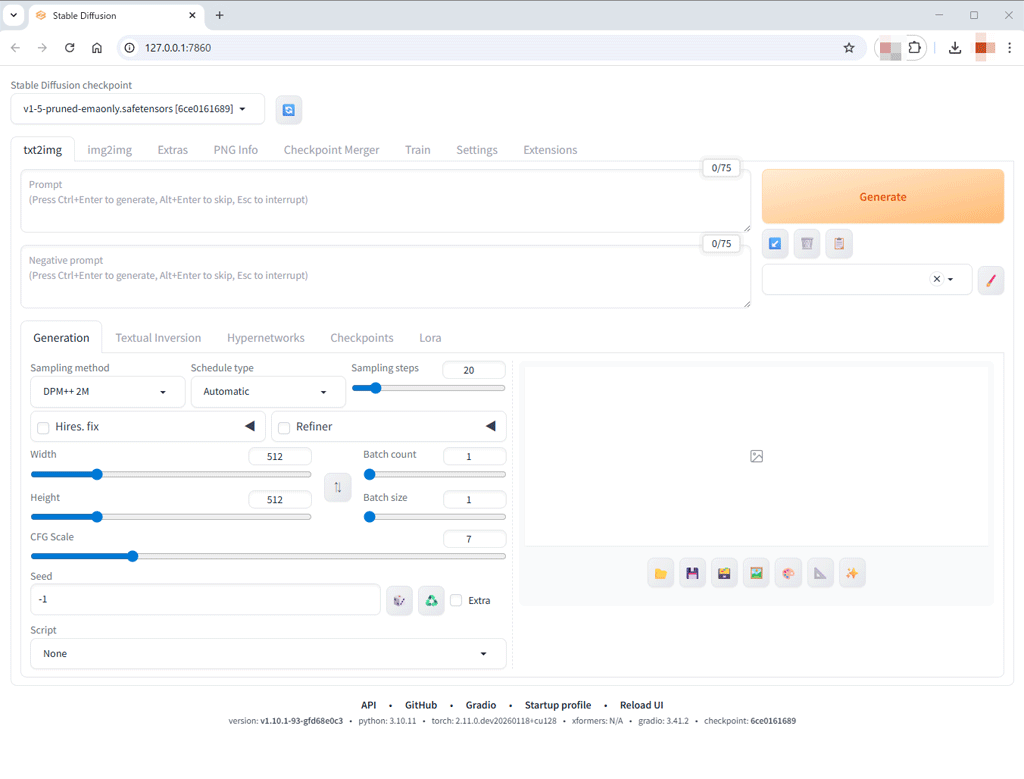
この画面が出れば、ひとまずは安心ですね。初回は、ここまでに何度かのエラーを味わいました。
URLは、 http://127.0.0.1:7860 となります。設定次第で、ローカルネットワーク上の他PCから接続することもできるようですが、結局、生成した画像の確認やモデルの追加など動作PCのローカルディスクでの作業が必要になりますので、他PCから操る場合でも、リモートデスクトップで接続して、そこのローカルでブラウザを開いた方が素直で無駄がない気もします。
※初回起動時に、「Torch is not able to use GPU」というランタイムエラーが出て終了することがありました。これは、起動時のチェックで落ちているようなのですが、一旦終了して再度 webui-user.bat で起動すると何事もなく起動することが多いのではないかと思います。再発は無いので、これ以上深追いはしていません。
いよいよですね。
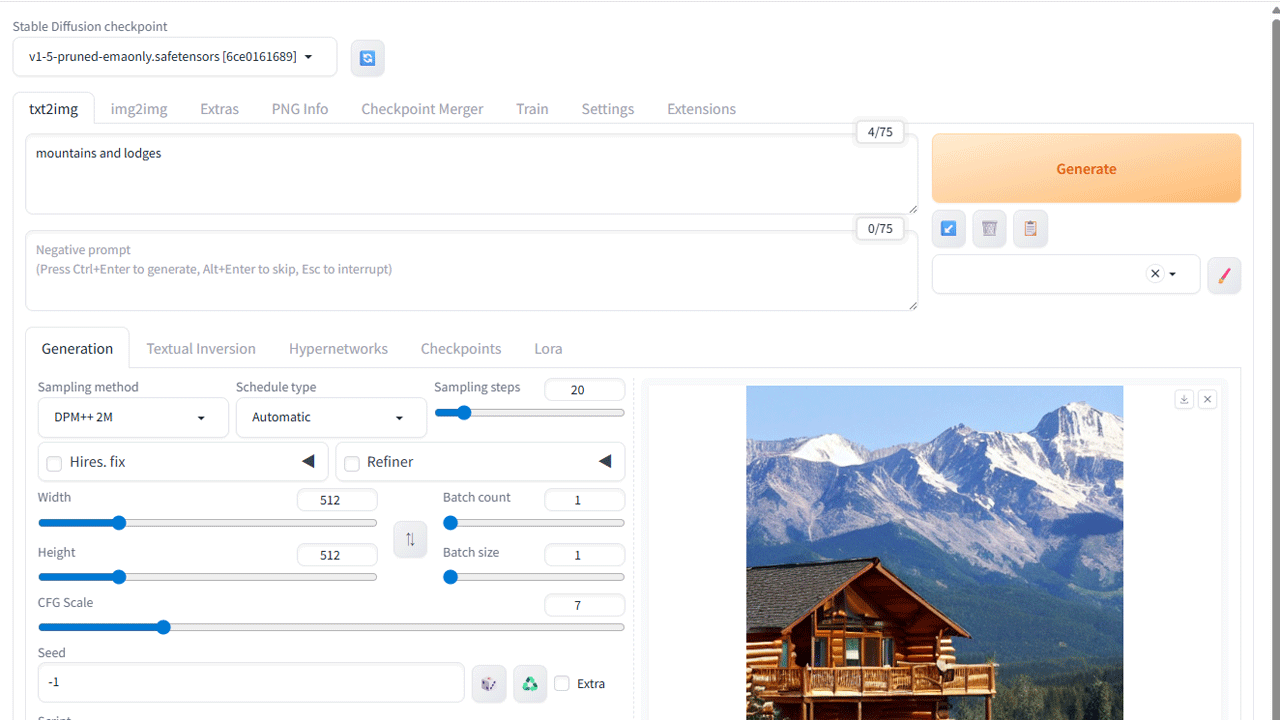
まずは、何もパラメータを触らず、プロンプトだけで生成します。
最終目標が人物の画像生成ではあるんですが、まずは、風景画を。
「Prompt」欄に「mountains and lodges」とだけ入力して、オレンジ色の「Generate」ボタンをクリックします。
SD1.5の512×512サイズの画像ですので、どこかのフォルダのファイルを開いたのかというくらいの速さで、プレビュー画面に表示されます。
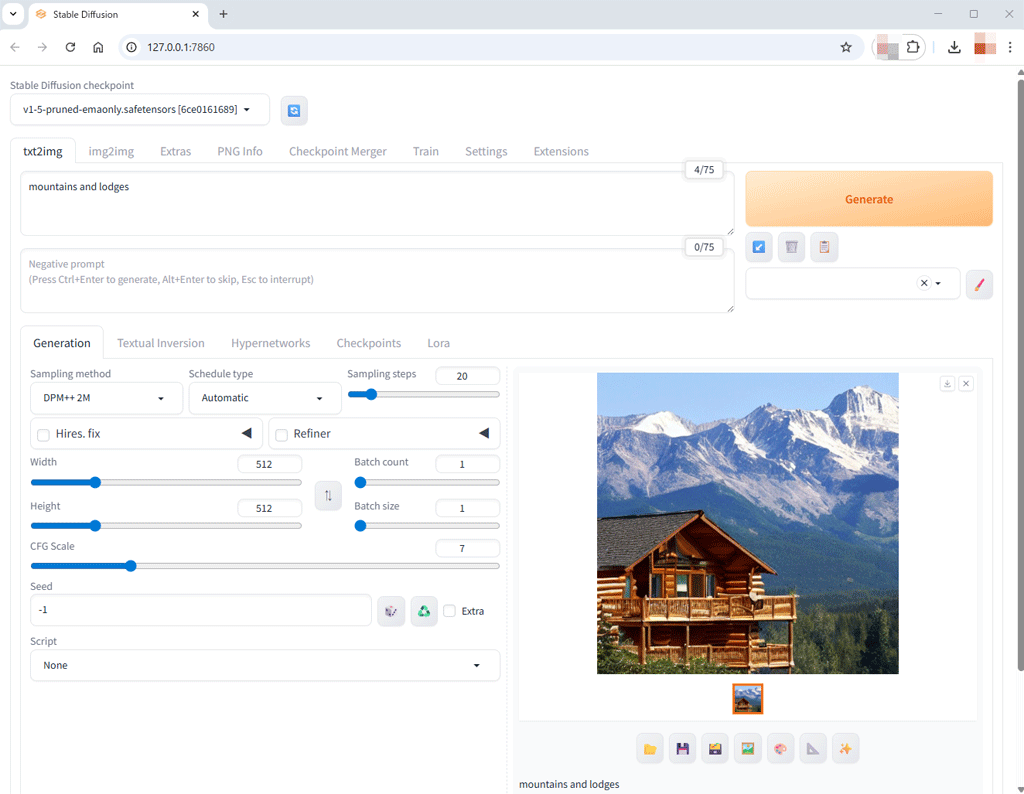
生成されたファイルは、標準で、
stable-diffusion-webui
└─ outputs
└─ txt2img-images
└─ YYYY-MM-DDに、生成日ごとに格納されます。png画像ですね。

自宅のローカルPCで、テキストから画像が生成できる。これは、ちょっとした感動です。
ちなみに、本当にGPUが使用されているのか、ということで、タスクマネージャーの動画生成時のキャプチャを貼っておきたいと思います。
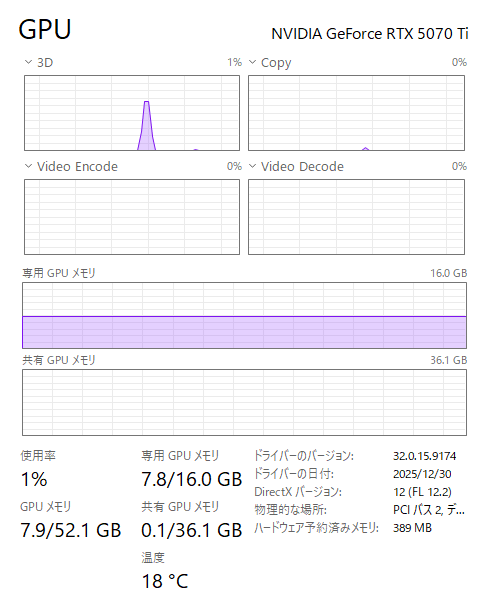
短時間ですが、GPUの稼働が上がっています。大丈夫そうですね。
というわけで、今回は、環境の構築まで実施しました。
次回は、頭に思い浮かべている(作成したい)画像を思い通りに生成できるか、というあたりにチャレンジしてみたいと思っています。
プロンプトだけで、思い通りの画像を作成できるのか。
人物画の生成を、プロンプトの試行錯誤で実施した記事はこちらです。併せてご覧ください。
