
kohya_ss でLoRAを作成する ~ 画像生成AI ③
ローカルPC上で画像を生成する Stable Diffusion の環境を作成して、何も手を入れていない素の(基本の)モデル、v1-5-pruned-emaonly.safetensors だけから、プロンプトの指示だけで、画像を生成することにチャレンジしたのが、前回の記事となります。

本記事に掲載している人物画像は、すべて生成AIにより作成したものであり、特定の実在人物をモデルにしたものではありません。
千三つでは困る…
前回の復習を兼ねて。

記事で最後に出したこの写真ですが、こんなに複雑なプロンプトを使用してました。(ChatGPTとの対話で積み上げてきた結果です)
prompt
a young adult japanese woman, portrait photo,
black hair, brown eyes,
simple straight hairstyle with minimal volume,
camera at eye level,
natural makeup,
attentive eyes with a calm, soft gaze,
calm and approachable expression,
slight smile as a natural response,
soft, friendly impression,
subtle jaw definition,
clean transition from jaw to neck,
front-facing or very slight angle, head upright,
soft facial structure, gentle facial proportions,
distinctively east asian facial features,
natural skin texture,
simple casual clothes,
clean but understated appearance,
indoor setting,
soft, slightly uneven natural light
negative prompt
anime, illustration, cartoon, CGI, render, doll-like,
overly generic, stock photo look,
fashion model, runway look,
sharp eyes, upturned eyes, overly defined eye shape,
strong smile, wide smile, teeth visible,
prominent cheekbones, strong jaw structure,
excessive volume on top,
puffy hair on top,
tall hair silhouette,
overly rounded jawline,
heavy jaw
ところが、です。
この画像が「Generate」ボタンを1クリックで出力されるならともかく、実際のところ、三百枚近くを出力しての1枚です。
さすがに、この先、ポーズや背景の変更などのためにプロンプトを変更して、期待する画像を出すために毎回数百枚を出力するのは現実的ではないので、何とかしたいところです。
千三つ。1000に3つ、というのは1000品目を出してヒットするのが3品目程度という食品業界や、1000件の話でビジネスにつながるのが3件ほどという不動産業界では、業務の「難しさ」を表していますよね。
300枚近く出しての1枚なので、千三つに近いんですが、この3をもっと上げるにはどうすればいいか、というのが今回のテーマです。
プロンプトの見直し
プロンプトが同じで、各パラメータも同じ、それと何より大事なSeedが同じなら、ほぼ同じ画像が生成されます。でもこれ、「同じ」であって、バリエーションが増えるわけではないんですね。それなら、Photoshopなどの画像編集ソフトや、もっと言えばWindowsのファイル操作でファイルコピーするのとそれほど違いがありません。
Seedを保ったまま、Sampling Stepsの数を微妙に変えたり、CFG Scaleの値を変えると、ほんの少し変わったりするんですが、同じSeedでも、サイズ(高さ・幅)を変えるとまるで別ものとなります。
例えばこちら。同じSeedのサイズ違いです。

どう見ても別人ですよね。
サイズを戻してSeedを同じにするとやっぱり同じ画像が生成されますので、もはや異なるサイズで同じ人物を生成するのは絶望的です。広さの違う畑に同じだけの種(Seed)を蒔いても、収穫量が違いますからね。ってそれはたとえになってないか。。
では、どうするか。
複雑なプロンプトから生成された1枚なので、逆に、「その画像の特徴を抽出して生成するプロンプト」を作成すればどうなるか、と、これまたChatGPTに丸投げしてみました。さすがに人の目では、主観が入りすぎて上手くいきませんので。
その結果、編み出されたのがこちら。
prompt
photorealistic portrait of a young adult japanese woman,
studio-quality photo,
straight black hair, medium length,
hair tucked behind both ears,
center part, minimal volume,
almond-shaped dark brown eyes,
gentle eye expression,
slightly lifted outer eyelids,
bright clear eyes,
small straight nose,
natural lip thickness,
subtle natural smile,
corners of lips slightly lifted,
slightly oval face shape,
soft but healthy jawline,
smooth jaw-to-neck transition,
natural healthy skin tone,
light natural makeup,
camera at eye level,
front-facing, head upright,
professional headshot composition,
upper torso framing,
wearing a simple dark business suit jacket,
neutral indoor background,
soft diffused natural light,
confident and calm presence
negative prompt
anime, illustration, cartoon, CGI, render,
doll-like skin, plastic skin,
fashion model look,
runway makeup,
strong smile, wide smile, teeth visible,
sharp jaw, square jaw,
prominent cheekbones,
very large eyes,
upturned eyes,
heavy eyeliner,
puffy hair, high volume hair,
messy hair,
overexposed, harsh lighting,
stock photo watermark
sad expression,
depressed look,
tired eyes,
droopy eyelids,
downturned mouth,
frown,
worried expression
このプロンプトで何枚かを生成してみたんですが、その中で比較的雰囲気が近いのがこの写真でしょうか。

それでも、「同じ人」というにはちょっと無理があります。
プロンプトは、
(almond-shaped dark brown eyes:1.2)
このように、括弧でくくって、後ろに 「:数値」(1を中心に弱め・強め)とすることで、そのプロンプトの重みを調整することができます。そんな調整をしばらく続けてみたんですが、安定して同じ人物の顔を生成する、とは程遠いのが実情ですね。
プロンプトだけで「同じ人物の顔」を再現するのは、難しい(可能性がゼロではないとは思いますが…)という結論でよいかと思います。
人物の顔を学習する
そうすると、Stable Diffusion で特定の顔を生成しようとすると、その人の顔を学習するしかありません。
Stable Diffusion では、モデルに対する差分を付加する仕組みがあります。それが LoRA です。
正式には Low-Rank Adaptation と言うそうですが、略したLoRAで十分に通じます。読みはローラですね。ローラというと西城秀樹さんの「傷だらけのローラ」とかを思い出しますが(って、リアルタイムに聞いた世代ではないですけど)、こちらは Lola、女性の名前ですね。綴りが違います。
そんなことはどうでもいいんですが、モデル(今回では、v1-5-pruned-emaonly.safetensors)には直接手を入れず、追加学習させるための仕組みなので、モデル本体が 4GBほどあるのに対して、LoRAは数MB~数百MB程度の大きさに収まります。
しかも、その重みを自由にコントロールできますので、調整もしやすいとのこと。
期待が持てます。
LoRAというと、Civitaiなどでほかの人が作成したのを入手するもの、というイメージが強かったんですが、自ら作ってみるのも面白そうです。
では、何で作るのか、というと、「kohya_ss」という学習ツールを使用するのが一般的、というのか分かりやすいようです。
では、まずは、kohya_ssを導入するところから始めてみましょう。
kohya_ssの導入
Git と Python3.10 が必要ですが、これは既に導入済みのはず。
C:\AI の直下でもいいんですが、この先、いろいろなツール類が増えそうな気がしたので、C:\AI\toolを作成して、そこに移動。ターミナル(コマンドプロンプト)を開いて、
git clone https://github.com/bmaltais/kohya_ss.gitとします。あっという間に、ダウンロードが完了するかと思います。
次に、Python 3.10 を指定して、仮想環境(venv)を作成します。
cd kohya_ss
py -3.10 -m venv venv
venv\Scripts\activate
python -m pip install -U pip setuptools wheelRTX 5070 Ti を使用していますので、ここで先に、cu128のPyTorchをインストールしておきます。
python -m pip install --index-url https://download.pytorch.org/whl/cu128 torch torchvision torchaudioこの後、念のために、GPUの認識をチェックしておきます。
python -c "import torch; print('torch',torch.__version__); print('cuda',torch.version.cuda); print('avail',torch.cuda.is_available()); print('gpu',torch.cuda.get_device_name(0) if torch.cuda.is_available() else None)"これで、
torch 2.10.0+cu128
cuda 12.8
avail True
gpu NVIDIA GeForce RTX 5070 Tiこのように出ればOKですね。
venvの環境は一旦抜けて、ダウンロードされた setup.bat を実行します。
が、実施するタイミング(取得時のリビジョン)に依るのかもしれませんが、
Traceback (most recent call last):
File "C:\AI\tool\kohya_ss\setup\setup_windows.py", line 7, in <module>
import setup_common File "C:\AI\tool\kohya_ss\setup\setup_common.py", line 8, in <module>
import pkg_resources
ModuleNotFoundError: No module named 'pkg_resources'というエラーが出て止まりました。
pkg_resourcesが見つからない、というものですね。
ここまでの手順で、setuptoolsが入るんですが、バージョン 82.0.0 には、pkg_resourcesが同梱されていないそうです。そのため、それが同梱されているsetuptools(80.x)に戻すのが手っ取り早いそうで、venvの環境上で、
python -m pip install --force-reinstall "setuptools<81" wheelとします。そのあと、
python -c "import pkg_resources; print('OK', pkg_resources.__file__)"として、OKの表示が出れば、問題解決です。
では、気を取り直してもう一度。setup.batを実行します。
Kohya_ss setup menu:
1. Install kohya_ss GUI
2. (Optional) Install CuDNN files (to use the latest supported CuDNN version)
3. (DANGER) Install Triton 2.1.0 for Windows... only do it if you know you need it... might break training...
4. (Optional) Install specific version of bitsandbytes
5. (Optional) Manually configure Accelerate
6. (Optional) Launch Kohya_ss GUI in browser
7. Exit Setup
Select an option:ここは悩まず、「1. Install kokya_ss GUI」で、1です。
少しばかりインストール(ダウンロードも含む)に時間がかかった後、それまで順調だった最後の最後にエラー表示が。

どうやら、バージョン不整合を指摘されているようです。というわけで、指摘されている torch、torchvision、torchaudioをいったん全部消して、指定バージョンのものを入れなおします。
pip uninstall -y torch torchvision torchaudio
python -m pip install --index-url https://download.pytorch.org/whl/cu128 torch==2.10.0 torchvision==0.25.0 torchaudio==2.10.0が、さらにエラー。
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
xformers 0.0.30 requires torch==2.7.0, but you have torch 2.10.0+cu128 which is incompatible.Automatic1111もそうなんですが、現状では5070Tiとxformersとの相性が良くないようで、xformersをアンインストールします。(無くても動きます)
python -m pip uninstall -y xformersそのあと確認として、
python -m pip list | findstr -i "torch torchvision torchaudio"これで、
lion-pytorch 0.0.6
open-clip-torch 2.20.0
pytorch-lightning 1.9.0
pytorch_optimizer 3.5.0
torch 2.10.0+cu128
torchaudio 2.10.0+cu128
torchmetrics 1.8.2
torchvision 0.25.0+cu128このように出れば、大丈夫なようです。
ここまで来れば、venvを抜けて、C:\AI\tool\kohya_ssにある、gui.batを実行すれば、大丈夫…
なはずなんですが、
Starting the GUI... this might take some time...のまま、しばらく固まってます。
ヒヤッとしたんですが、しばらくして動き出しましたので、待ちましょう。
* Running on local URL: http://127.0.0.1:7860最後に、このように表示されたら、ブラウザで http://127.0.0.1:7860 にアクセス。
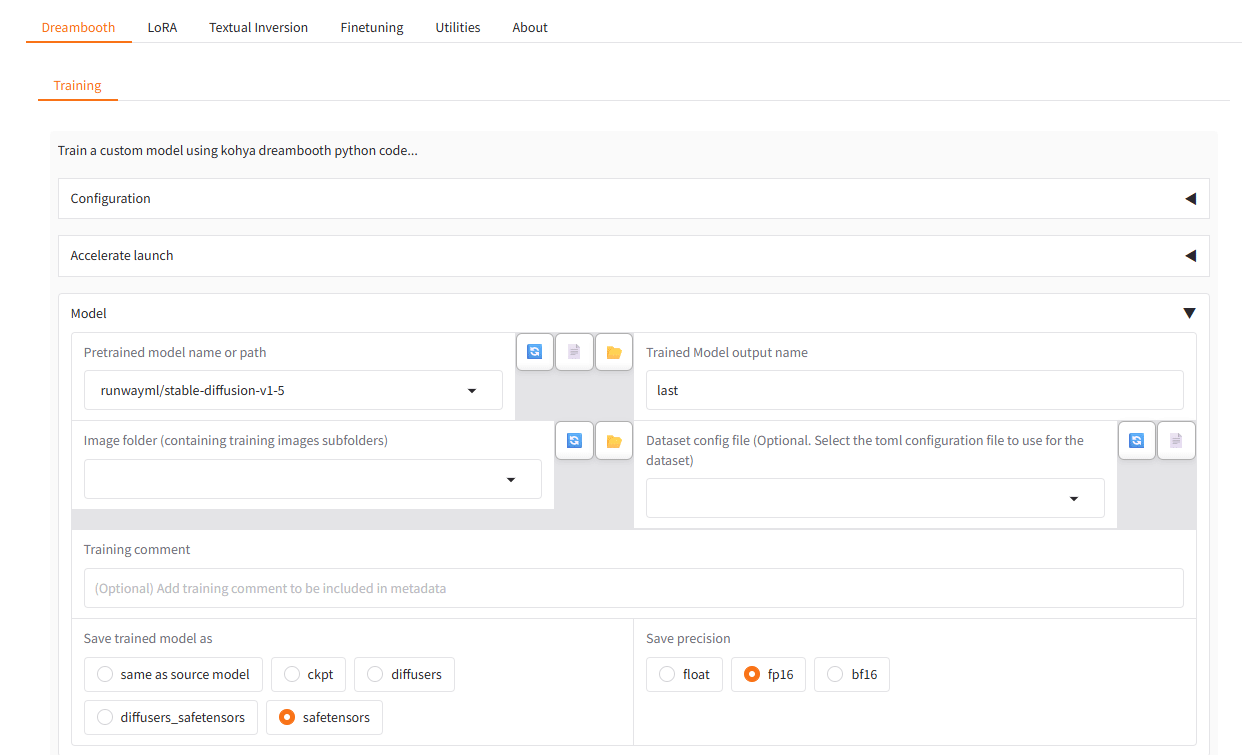
こんな感じの画面が表示されたら、成功です。
今回は、インストールの流れから実行まで行きつきましたが、2回目以降は、同じフォルダにある gui.bat で直接実行できます。
学習素材探し
と、環境が整ったところではあるんですが、まだ学習させる素材が無い状態です。
さすがに、1枚だけで学習できるとは思ってません。なので、最低でも5~6枚程度は「同じ人」の画像が欲しいところです。理想(当初、頭に思い描いていたもの)としては、その画像を生成したプロンプトで、何十枚か生成すれば、同じように見える人物が適度に生成できるんじゃないか、と。
ところが、千三つ状態ですので、さすがに何千枚も生成して同じ人物に見える写真をピックアップするのも、ちょっと現実的ではないですよね。
どうするか、の前に、LoRA学習について、少しだけ触れておきたいと思います。
学習させたい画像が1枚あれば、学習は不可能ではありません。
なのですが、学習に使用したい画像が1枚しかないと、どういうことになるかというと、その人の顔はもちろん、髪型、服装、背景、光の当たり具合など、要はその画像のすべてを、識別子と結び付けて学習してしまうことになります。
LoRA学習では、その画像と文字(テキスト)をどう紐づけるのかというと、学習させたい画像と対になるように、説明用のテキストファイルを作ります。そのファイルに、キャプションを記載します。その画像が何の学習のためのものかを説明するワードを並べる、という感じです。
例えば、今回は生成AIで作成した人物(ここから先は、ai_model_v1 という識別名で呼びます)を学習させて、LoRAを使用しての生成時にそのai_model_v1を表示させたい場合に、プロンプトで、その(作成した)LoRAを使用する、という宣言と、この識別子(ai_model_v1)を記載することで、学習した人物が生成される、という仕組みです。
ところが、いくらキャプションで「人物だけを学習して」のつもりで、human とか、man、woman、なんかを併せて書いたところで、ai_model_v1 は、背景部分を除外はできません。
素材が複数枚あって違う部分があると(例えば、背景が街の中か建物の中かで)その識別子は、共通する部分のものだな、という理解が強まります。要は背景が全く違うと、人物の特徴が相対的に強化されて学習される、というイメージです。逆に、1枚だと「違い」が無いので画像の特徴(重み)が算定できない、という感じでしょうか(複数枚を学習することで、毎回同じ部分は重要度が高い、と学習するような感じですかね)。
ということなので、複数あればOKか、というとそれだけでは無理で、それぞれの画像に違いが必要だ、ということになります。
体形や衣装込みで学習させたい場合は、同じ衣装で学習させる必要がありますが、逆に、服装を固定させたくない場合は、いろいろな種類の服装の写真を用意しておかないと、固定化されてしまう、ということになります。背景も同じで、いろいろなポーズや服装の写真を撮影しても、それが同じステージ上だと、その人=その背景という、非常に迷惑な覚え方をしてしまうんです。残念ながら、そういうものなんです。
ところが、です。
今回は1枚の画像から学習させよう、という無謀な企みですから、背景違いや服装違いも用意できていません。というか、できません。
要は、1枚じゃダメ、複数でも同じ写真だと固定化されてダメ、ってことで、頼ったのが、Stable Diffusion(Automatic 1111)に備わっている img2img 機能です。
img2imgでの画像生成
プロンプト(テキスト)から画像を生成するのがtxt2imgで、画像を基に別の画像を再生成するのがimg2imgです。
txt2imgの横にimg2imgタブがあります。
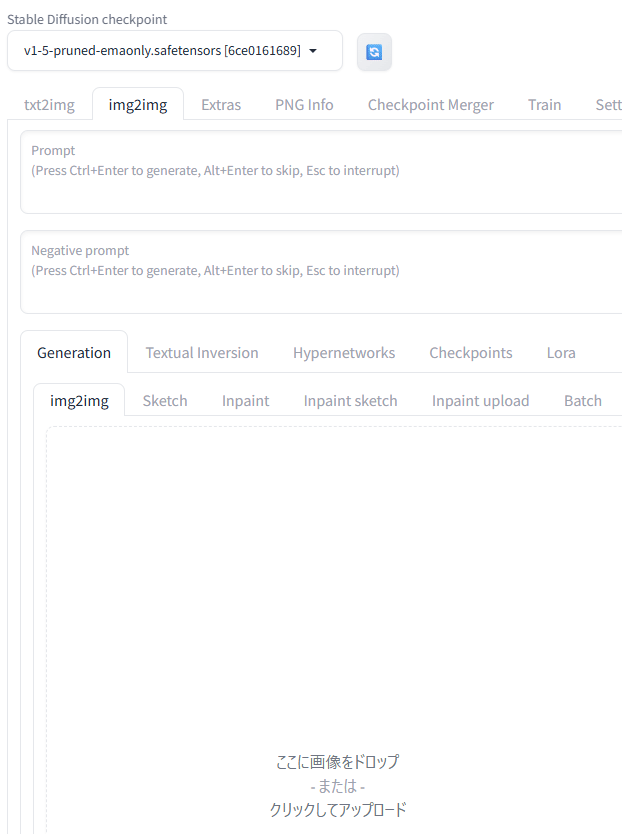
下には、Generationとあって、その中に、img2imgタブがあるんですが、ここに画像をドロップという枠があるので、そこに、元画像をドロップし、Promptに、変更したい内容を文字で記載します。
例えば、こんな感じですね。
prompt
slight closed-mouth smile,
looking slightly left
効きの強さは、さらに下にあるパラメータ Denoising strength で調整できます。元の画に、より忠実なのが0側、より強く影響させるのが1側、です。プロンプトに従わそうとこの値を強く(1に近く)すると、そもそもの画像を維持しようとする力も弱くなりますから、全くの別人になる可能性もあります。というか、なります。
結局、元画像から顔の部分を正方形にトリミングしたものベースとして、目元や口元の微妙な違いの写真を10枚ほど用意したんですが、背景や服装は同じまま。どんなことになるのか、ある意味、楽しみでもあります。
ファイル名は、例えば、「ai_model-1.jpg」など、LoRAの名前やキャプションと直接紐づける必要はありません。唯一紐づけるのが、キャプション用のファイル名です。
「ai_model-1.jpg」ならば「ai_model-1.txt」というファイルを作成します。
ここには、最低限、識別するための名称を記載すれば、それなりに学習してくれるようです。詳細に書くべきだ、という説や、簡素化すべしという説もありますが、その実は、よくわかりません。
ひとまず、当たり障りのないよう、全10ファイルとも、このようにしてみました。
ai_model_v1, portrait, japanese woman, young adult
このフォルダをどうするか、は次項に。
kohya_ssでの学習
まず、慣れるまで忘れやすいのが、このタブ切り替え。
Dreamboothではなく、LoRAに変更してください。Dreamboothは、モデルそのものに追加学習を加えるものですので、必要とするハード要件(VRAMサイズ)も格段に上がります
そのあとで、Trained Model output name に、LoRAファイル上の識別名称を、そして、Image folderには、学習用画像を収めたフォルダを指定するんですが…
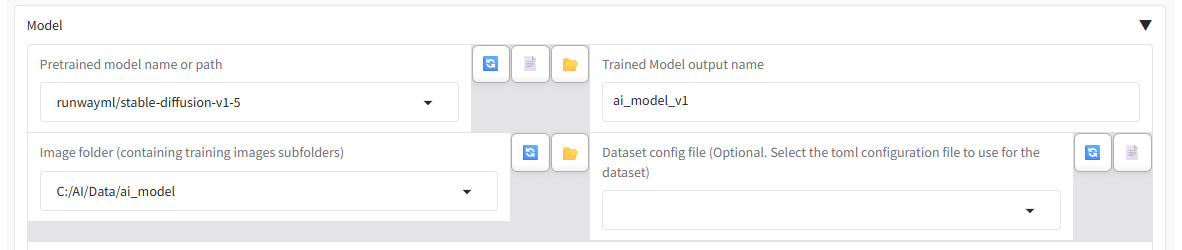
これ、最初、知らずにはまりました。
C:/AI/Data/ai_model の直下に、画像ファイル10個と、テキストファイル10個を置いて、この設定で実行すると、対象ファイルがない、と、エラーになります。
で、どうするかというと、C:/AI/Data/ai_model の下に、
(学習回数)_フォルダ名
という、フォーマット指定された名前のフォルダを作成して、その直下に各ファイルを入れる必要があります。
例えば、ここでいうと、C:/AI/Data/ai_model/1_ai_model_v1 のように。※フォルダ名は識別名称と一致させる必要は無いようですが、合わせておくと分かりやすいのかな、と思います。
回数の方もいろいろな流儀があるようですが、要は同じ画像を何回学習に利用するか、というもので、10とするのを勧めているところが多いのではないでしょうか。少ない画像でも、十分な回数の学習を重ねることができる、という理由です。
正直なところ、違いはよくわかってないんですが、私は、別のパラメータで回数を増やすので、ここでは、1_を指定しています。
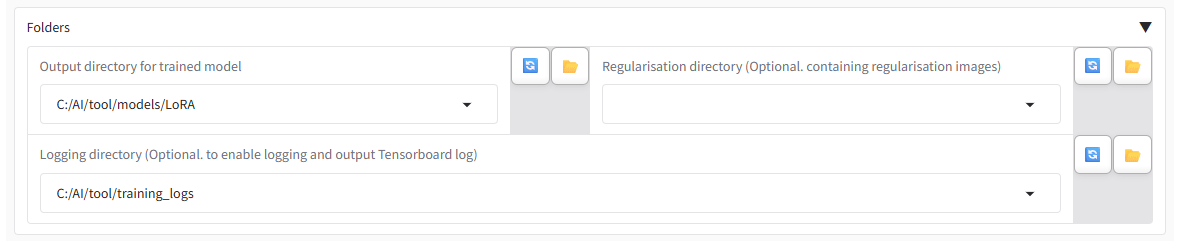
その下にある項目 Output directory for trained model には、生成したLoRAファイルを格納する用のフォルダを指定します。事前に作成しておいてください。
すぐ下のログ保存フォルダも、今後のことを考えて設定しておくと良いかと思います。
他に必須の修正箇所は一番下の「Parameters」を開けたところにあります。
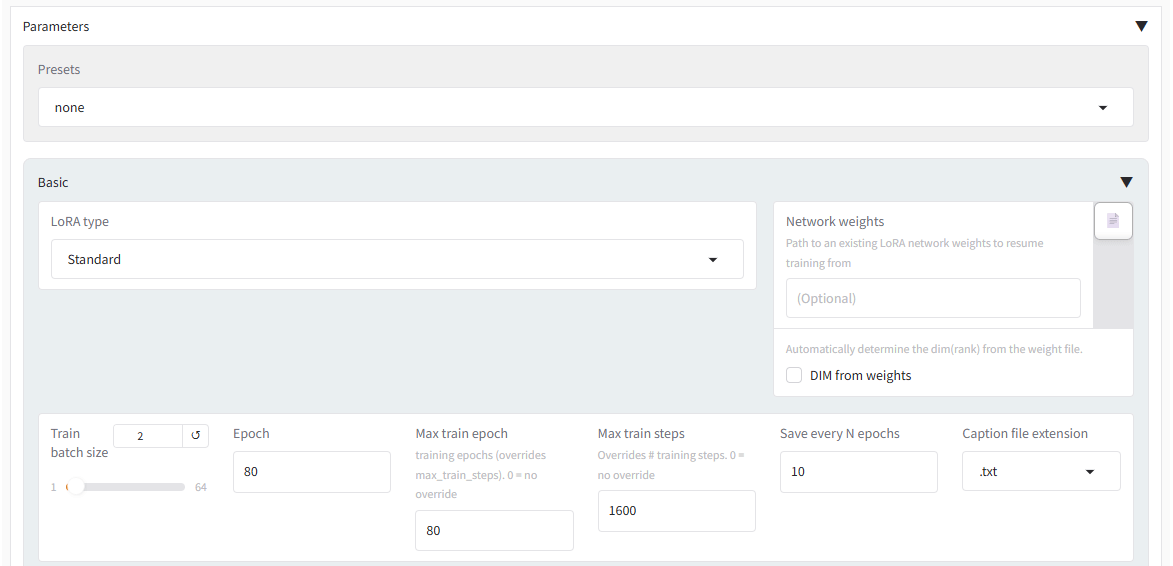
Train batch sizeは、VRAM16GBの5070Tiなら、2で大丈夫かと思います。実はもうちょっと高い値でも学習可能なんですが、一説には並行して学習を行うよりもbatchが低めの方が安定する(画像差分を認識しやすい)、という話もあるようで、2としています。
上部で、画像当たりの学習の回数を10_とした場合はepochは、8程度で十分だと思いますが、先ほどの理由から10倍の80としています。で、右側にある「Save every N epochs」も10倍の10としています。
epochとは、学習素材の画像を一通り見終わる単位、という感じで、リピートが10回で素材が10枚なら、1枚を1回学習するのが1stepですので、全部で100step = 1epochとなります。
リピートなしで素材が10枚なら10stepで1epochとなりますから、リピート10回のときよりepochの進みが10倍速くなるということです。もちろん、学習が10倍速いという美味しい話ではなく、学習速度はおおよそstep数に依存するとのことです。
「Save every N epochs」は、学習途中のLoRAを、どの周期で保存する(残しておく)か、という指示で、「必ずしも回数を重ねることが質を高めることにならない」というLoRA学習の難しさを象徴していると思います。途中の生成物も残して、最善のものを選択する、ということですね。
その少し下にある、「Network Rank (Dimension)」と「Network Alpha」は、「32」としています。これがベストかどうかはわかりませんが、学習効果を強めに働かせる意図での設定です。
パラメータの数は、他にも山のようにありますから、極めるには程遠いですが、まずは、こんな感じで進めたいと思います。
ここまで設定したら、いったん最上段に戻って、Configurationを開いて、Config Fileとして保存しておくことをお勧めします。次回以降、このファイルを開くことで、そこまでの設定が完了した状態となります。

最後に、もう一度下に戻って「Start Training」をクリックします。
初回は、大きめのファイルのダウンロードなどもあって、時間がかかります。
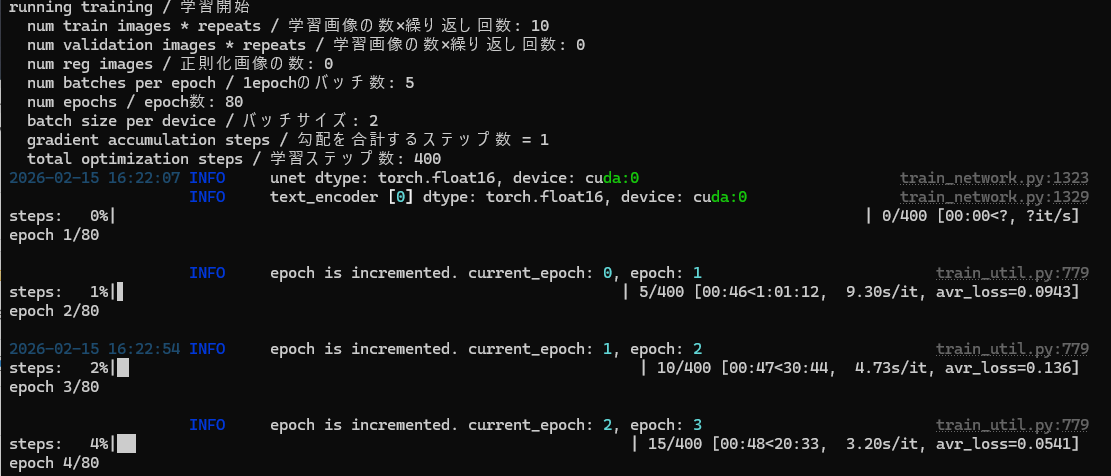
こんな感じで進みだせば、あとは完了を待つだけです。
残り時間も表示されますし、特に心配も要りません。ここまで来て途中で止まったことは、今のところ無いですね。
最後まで終わると、指定したフォルダに、このようなファイルが生成されています。
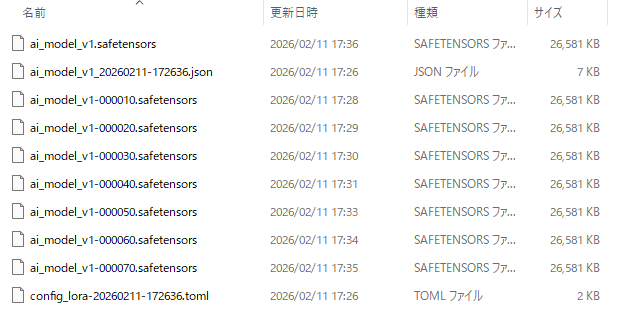
拡張子 .safetensors が LoRAファイルです。 .json と .toml には、生成時のパラメータが記録されています。
LoRAファイルのうち、-0000xx が無いのが、いわゆる最終形で、-0000xxとあるのが、途中段階での生成ファイルです。といっても、ビルド時の中間生成ファイルというようなものではなく、それぞれが単独でLoRAファイルとして使用できる「途中段階での完成形」ではあります。
今回は、話が長くなってきたのでここまでとして、次回は、複数生成されたLoRAファイルの中から最適なものを見つけるところからスタートしたいと思います。
…と言いたいところですが、ここで終わってしまうと、ちょっとモヤモヤしそうなので、実際にLoRAとして機能するかどうかだけ、チェックしてみたいと思います。
最終形のLoRAファイルを、
stable-diffusion-webui
└─ models
└─ Lora
└─ ai_model_v1.safetensorsに置きます。
それから Stable Diffusion(AUTOMATIC1111)を起動します。※起動後にLoRAファイルを所定の場所に置いた場合は、再読み込み処理が必要です。
prompt
<lora:ai_model_v1:1.0>, ai_model_v1, portrait, japanese woman, looking at viewer
negative prompt
low quality, worst quality
これだけで、

この画像が生成できました。複数枚生成しても、ほぼ同一人物で生成されます。しかも、あれだけ大量に必要だったプロンプトが、たった1行になったわけです。さすがはLoRAですね。
といっても、一見成功に見えて、実は問題が山積なんですが、それは次回に、ということで。。
一見上手く行ったように見えたLoRA作成。実は思わぬ落とし穴がありました。その確認と解決に向けての対応を行った話はこちらになります。併せてご覧ください。
