
最適なLoRAを求めて ~ 画像生成AI ④
ローカルPC上で画像を生成する Stable Diffusion で、素の(基本の)モデル v1-5-pruned-emaonly.safetensors へのプロンプトの指示だけでは期待する画像が生成できないことから、kohya_ssによる学習を行い、LoRAを作成することで、期待する「顔」が表示されたところまでが、前回の記事となります。

画像生成のための Stable Diffusion の環境を作成するところから(このシリーズの初回)は、こちらをご覧ください。
本記事に掲載している人物画像は、すべて生成AIにより作成したものであり、特定の実在人物をモデルにしたものではありません。
最適なepoch数のLoRAを見極める
前回の記事で、最後に生成された画像がこちら。

顔アップの生成を実施
これで期待通り、大成功じゃないの?と思ったのも束の間、これではダメだ、と気づきました。その話は一旦置いておいて、まずは、そこに行きつく前に、セオリー通り、どのepoch数で作成されたLoRAが最適か、を見極めたいと思います。
その方法は、シンプルですが、「それぞれのLoRAで同じ画像を出してみる」ということに尽きます。
使用するプロンプトは、ChatGPTの勧めで、次のようにしてみました。
prompt
portrait, close-up, headshot,
looking at camera, neutral expression,
soft studio lighting, sharp focus, high detail skin,
50mm photo, realistic,
neutral expression
negative prompt
worst quality, low quality, lowres, jpeg artifacts, blurry,
extra digits, fewer digits, bad hands, bad anatomy, deformed,
multiple faces, duplicate, extra limb, long neck
それから(というか、こちらが先ですね)、LoRAファイルを下記のフォルダに置くんですが、
stable-diffusion-webui
└─ models
└─ Lora後々のことを考えると、Loraの下に、testとかというような、わかりやすいフォルダを作って格納しておくと良いかと思います。
ちなみに、Stable Diffusionは、models/Loraの下では、フォルダは意識しないようで、ファイル名でしか判別しません。なので、異なるフォルダに同一名のLoRAがあると、どれが使用されているのかわからない状態となるようです(特にエラー表示とはなりませんでした)。そこだけは注意ですね。
というわけで、models/Lora/test に、生成された ai_model_v1.safetensors と、ai_model_v1-000010.safetensors から ai_model_v1-000070.safetensors の枝番がついた LoRAファイルをすべて、置きました。
先ほどのプロンプトにはLoRAについての記載がありませんので、プロンプトの先頭行に追記します。
prompt
<lora:ai_model_v1-000010:0.2>,ai_model_v1,
(以下略)
手作業で入力しても大丈夫なんですが、ネガティブプロンプトの下にある、「Generation」~「LoRA」が並ぶタブで「LoRA」を選択し、そこからチョイスする方が確実です。きちんとStable Diffusionに認識されているLoRAだ、と確認できますので。
逆に、LoRAファイルを置いたはずのフォルダに表示されていなければ、まだ Stable Diffusionが認識できていない、ということになりますから、

右側にある、くるっと回るアイコンをクリックして、再読み込みを実施します。すると、格納したLoRAが一覧で表示されますので、まずは最も若い番号のLoRAを選択。

プロンプト欄の末尾に <lola:ai_model_v1-000010:1> のように追記されます。※同じLoRAを選択するとプロンプトから消えますので、焦らないように。。
<lola:ai_model_v1-000010:1> を先頭行に移動して、識別子(トリガーワード)として学習時に書いたキャプションを書き加えます。
上記プロンプトの場合、1番目に(epoch10のタイミングで)生成されたLoRAを、効き具合(weight)0.2で適用した画像が生成されます。
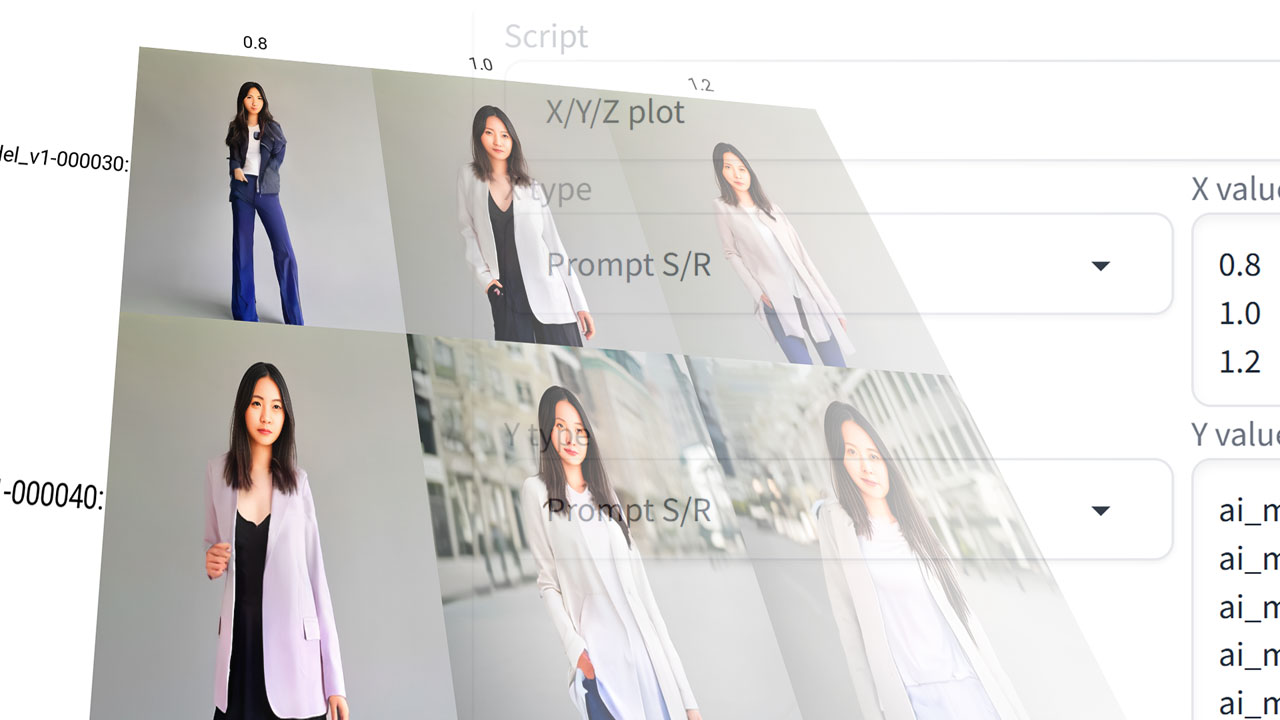
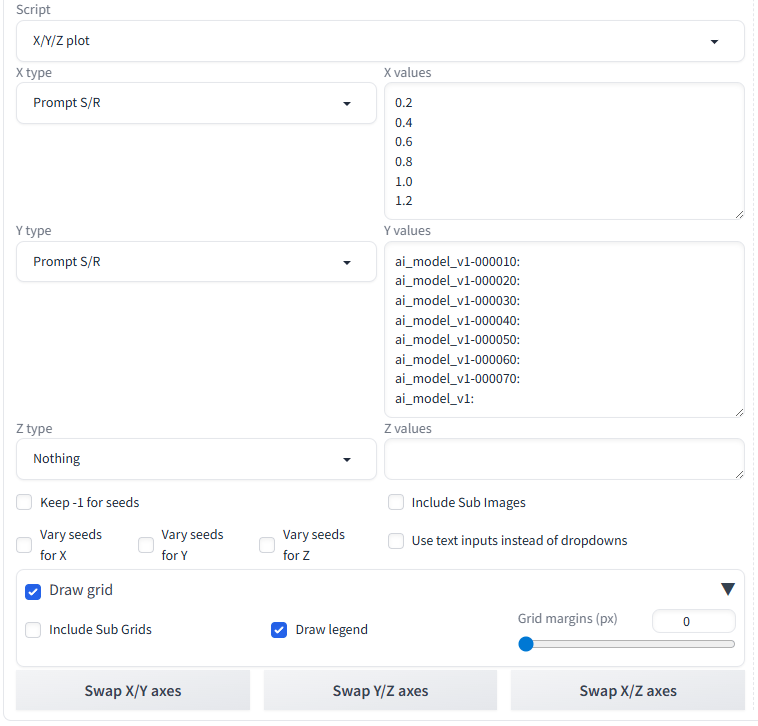
これを、000010~000070と枝番なしの8パターン、効き具合は 0.2、0.4、0.6、0.8、1、1.2で6パターンくらいをマトリクス状にかけ合わせて生成すると、「ベストに近いLoRA」が見えてきます。
うわぁ、めんどくさそう。。ですよね。計48パターンを手作業でするのは面倒以外の何物でもありません。
「X/Y/Z plot」で手軽にパターン化
で、AUTOMATIC1111には、その「めんどくさそう」を解決してくれる仕組みがあります。それが、スクリプト処理、「X/Y/Z plot」です。
txt2imgの最下段に、

というスクリプト選択項目があるので、そのプルダウンメニューから「X/Y/Z plot」を選択します。
すると、一気に設定項目が増えます。
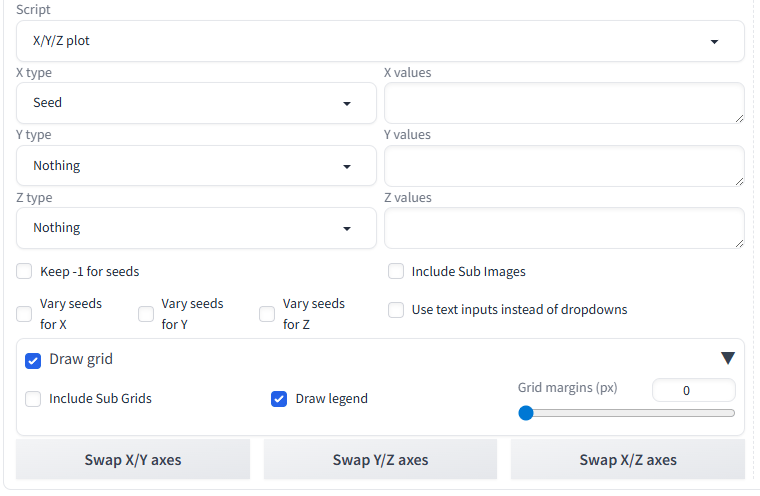
項目名の通り、自動処理をしてくれるスクリプトの設定を、GUI上でできる、かなりお役立ちの項目です。
何をするものかというと、今回の例では、epochの10~70と枝番なしの8パターンと、効き具合(weight)の0.2、0.4、0.6、0.8、1、1.2の6パターンを掛け合わせて、画像生成ごとにパラメータを変えながら自動実行してくれる、というものです。
今回は、プロンプトの一部を、生成ごとに置き換えていく「Prompt S/R」というものを使用します。
例えば、プロンプトに書いた、ai_model_v1-000010: を、ai_model_v1-000020: → ai_model_v1-000030:と置き換えていく感じです。下記のように、変更したい内容を、「Shift+Enter」の改行で並べていくだけ。
面白いのが、1行目に記載する文言がプロンプト上にある「置き換えワード」になるんですが、1行目そのものも処理される、ということです。
それともう一つ、面白いというか、若干の違和感があったのが、下記の設定で、処理される順番です。
Xがひとつ進む間にYがどんどん進んでいくのではなく、Yがひとつ進む間に、Xが順次処理される、というXよりもYが強い状態、ということです。なので、下記の場合、
<ai_model_v1-000010:0.2>
<ai_model_v1-000010:0.4>
:
<ai_model_v1-000010:1.2>
<ai_model_v1-000020:0.2>
:
の順で生成されます。人にも依るかもしれませんが、同じLoRAファイルでweightを変えながら生成するのを全ファイルで繰り返す、という方が直感的に理解しやすいかと思いますので、この順で記載しました。
他の設定は、このようにしました。
DPM++2M/Karras
ステップ数:20
CFG:6
サイズ:512×512
Seed:123456789
Seedは、値は何でも構いませんが、必ず固定値を設定します。ランダム(-1)だと、意図した比較ができなくなる可能性があります。
では、いざ生成。
48枚の生成に1分49秒。さすが、速いです。512×512のSD1.5ですからね。
生成されたファイルは、\stable-diffusion-webui\outputs\txt2img-images の日付フォルダに出来るんですが、確認したいのはそれではなく、\stable-diffusion-webui\outputs\txt2img-grids に出来る、グリッド表示のもの。
左と上にグリッドの設定値が表示されますので、非常に見やすいです。txt2img-imagesフォルダに出来る1枚1枚を画像で見ると、そのパラメータは見えないですからね。
このようなファイルが2つ生成されます。
ひとつがJPEGファイルでもうひとつがPNGファイル。PNGファイルには、生成時のプロンプトや X/Y/Z plot での設定値も刻まれていますので、便利ではあるんですが、サイズが非常に大きくなるのが難点ですかね。
上記のファイルも、jpgが1.3MBほど、pngが15.6MBほどでした。
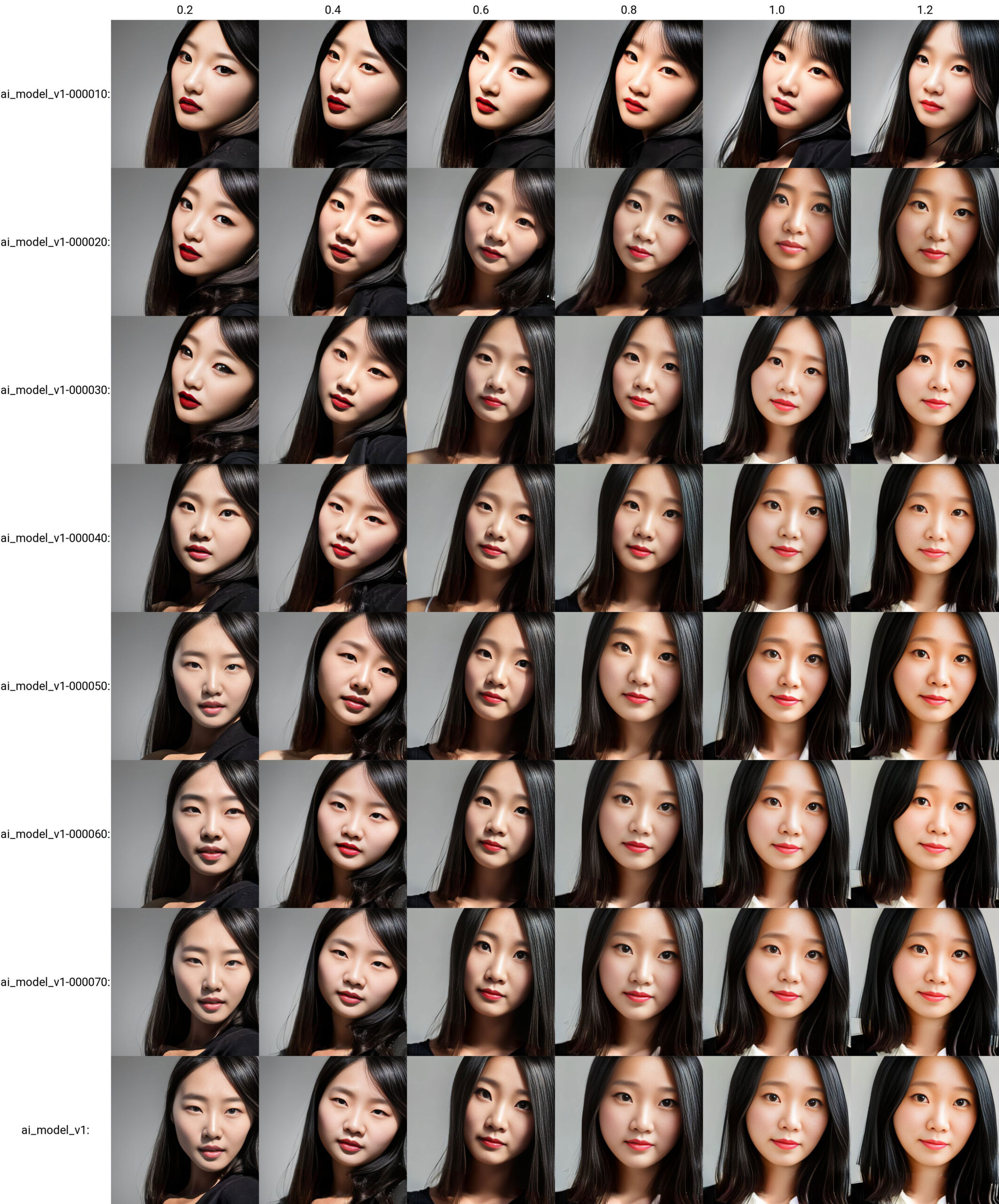
サイズはともかく、肝心の画像について見てみたいと思います。10枚の限りなく似た構図の画像から生成したとは思えないバリエーションができています。
ちなみに、学習素材の画像はこちら。いずれも512×512のものとなります。

1枚の画像から、img2imgを使用して、ちょこっとずつ変えたものですが、ほとんど「同じ」と言っても良い写真ですよね。。
この10枚の画像を学習したLoRAを使用して生成しても、weightが0.2や0.4のものは、ベースモデルの比重が高くなるので、LoRAが反映しにくい、ということです。逆に、0.8以上のものは、しっかりと効いてきます。
epochが10のものは、10枚の画像を10回ずつ、計100回(Step)の学習を繰り返したLoRAということになりますが、やっぱり、回数に応じた分だけしか学習しきれていない、ということが言えるかと思います。それでも weight 1.2のものは、特徴を掴みかけているので、わずか1分前後で生成できるLoRAにしては、上出来ではないでしょうか。
とはいえ、全体を見ると、weightの0.2~0.6や、ai_model_v1-000010/000020はちょっと使いづらい(別人化している)かな、と。
上半身の生成を実施
というわけで、これらを選抜して、もう少し引いた、上半身を出力してみます。
プロンプトは下記のように、変更しました。最後の行は、学習時の衣装から変更できるか、を試すためのものです。
prompt
<lora:ai_model_v1-000030:0.8>,ai_model_v1,
upper body, from chest up,
looking at camera, natural posture,
simple plain background,
soft daylight, realistic photo, high detail,
casual clothes
LoRAに関しては、開始をepoch 000030と、weight 0.8 にするため、変更しています。
ネガティブプロンプトは同じです。
X/Y/Z plot は、Prompt S/R の X values からは、0.2~0.6を削除、Y values からは、000010と000020を削除しています。
その他の設定は変えずに、生成実行。
トータルで3×6の18枚になったので、46秒ほどで終了です。
で、その結果は…。

むむむ?明らかに胸部以上の上半身はweightが0.8のものと、1.0のごく一部しかありません。逆に、顔が同一人物と見えるものは、上半身というプロンプトにもかかわらず、顔部分しか表示されない、という結果になっています。
服装も、weightが低いものはプロンプトの指定通りカジュアルなものですが、高いものは学習時のスーツ姿です。
要は、顔の効きを強めようとすると、構図や服装までもがセットで反映されてしまう、ということです。
なんか結果を見るのが恐ろしいですが、続いて全身を…。
全身の生成を実施
全身を表示させるため、プロンプトをこのように変更しました。
prompt
<lora:ai_model_v1-000030:0.8>,ai_model_v1,
full body, standing,
looking at camera,
simple background, full-length photo,
realistic, high detail, sharp focus,
standing, front view
他の設定は変えずに、さっそく生成。

full body, standing って、全身での立った姿勢ですよね。。
ちなみに、もしやと思い、weightを0.2まで引き下げたものを生成してみましたが、全epochのものとも、顔は似ても似つかないのに上半身しか表示されない、という結末に終わりました。
つまりは、LoRAの有無にかかわらず、このSeed値が、全身と指示しても上半身を生成するものだった、という可能性があります。
なので、別のSeed値でも試してみます。
Seed値を 12341234 として、同条件で生成してみました。

いい感じになりました。姿勢に関しては。
epochの30と40は、ちょっと顔が怖いですが…。
学習を深くした50あたりになると顔の雰囲気が良くなってくるんですが、weightが1.0でも、同一人物かというと「?」が付きます。同一人物だと言えるのはweightを1.2にしたときだけですが、そうすると、やはりLoRA生成時の構図に引っ張られてしまいます。
第1弾の出来栄えとしては、似た「顔」の生成はできたけれど、姿勢や服装の制御は壊滅的、という感じでしょうか。
これがLoRAの現実です。顔だけでの学習は、厳しいものがありますね。(あくまでも、SD1.5を使用しての個人的な見解です)
上半身画像での学習に再チャレンジ
まさかそんな結果になるなんて思ってなかったので、「顔中心に学習した方が効果的では?」と、敢えて顔中心にトリミングをしていました。
実は、元の画像は

こちらにもある通り、顔だけでなく、もう少し引いた画像で、胸のあたりからの上半身となっています。
LoRAの学習は、素材の「同じ部分」が多ければ多いほど、その重なる部分がトリガーワードの特徴だ、と覚えてしまいます。なので、画面に対しての顔の比率が同じ写真だけを学習すると、他に情報無いわけですから、このトリガーワードはこの顔比率も特徴として持っている、という、意図しない情報も紐づけてしまうんですね。
だからweightが1以上の生成画像が顔中心だったのは、半ば当然と言える結果ではあります。
なので、元画像が上半身なら、それを使わない手はありません。
元の10枚に加えて、同数程度の上半身画像を加えて20枚規模にします。が、ここでも問題が。なんせ、「同じものは、そのトリガーワードの個性」として学習するので、元画像に顔の表情などを少々変えただけでは「スーツ姿」しか出ない恐れがあります。先ほどの例からしてもそうですよね。
なので、衣装を変える作戦に出ました。
どうするのかというと、前回、目元・口元を変更するのに使用した「img2img」の「Inpaint」で、体部分をごっそりと書き換える、という作戦です。
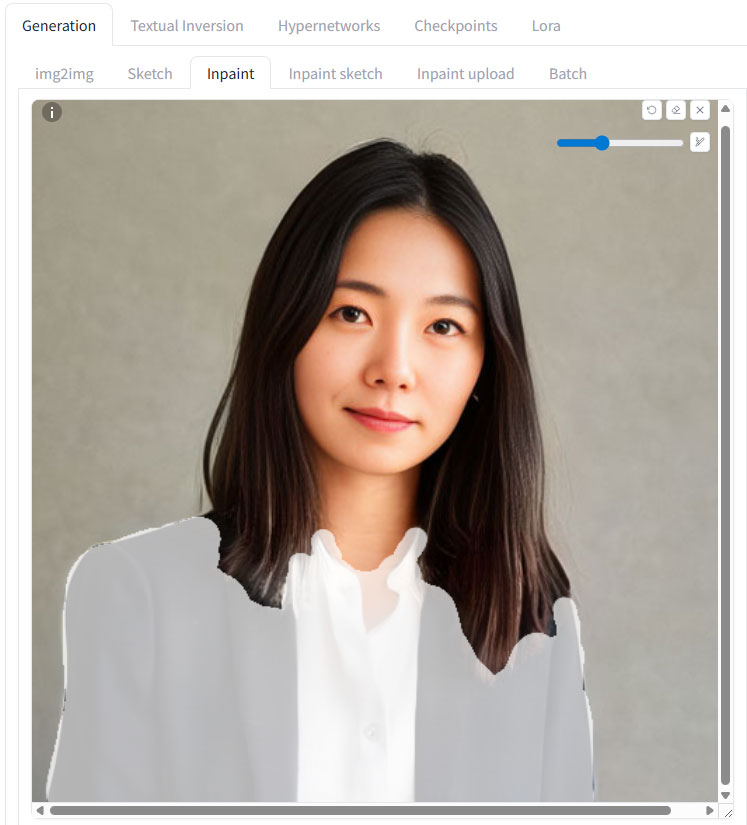
こんな風に、洋服部分をマスクして、プロンプトに
prompt
brown coat
とだけ書き、パラメータを
DPM++2M/Karras
ステップ数:20
CFG:6
Denoising strength:0.9
サイズ:512×512
Seed:-1
として生成すると、

こんな写真が簡単にできてしまいます。ちなみに、Denoising strengthを高めにしたのは、顔と違って、衣装は大胆に書き換えたいから、という狙いです。
調子に乗って、顔と髪の毛の部分をマスク(着色)して「Inpaint not masked」にすると、顔(+髪の毛)以外全部、となりますから、

こんなこともできたりします。ちょっとマスク処理がいい加減だったので境界部分が不自然ですが、今回の目的は、服装と背景を「バラけさせる」ためですので、顔以外に不自然なところがあっても、多少のものはOKなのかな、と思います。
それともう一つ大事なのが、全身像っぽいものを素材に含めること、です。
上半身のものは元画像があるので何とかなったんですが、腰より下は、完全に創作するしかありません。
上半身の画像をベースに、Photoshopでカンバスサイズを下に広げて保存し、それをimg2imgのInpaintで人型にマスクして生成すると、

なんか、それっぽいのができました(最後に512×512にリサイズしてます)。ちょっと違和感はありますが、これも、「このトリガーワードには下半身もあるよ」ということを学習させるためのものなので、多少の不自然さは大丈夫なのかな、と思います。
というわけで、全身(というか、これくらいの腰丈くらいまでのもの)を3枚用意し、顔アップ10枚、上半身10枚、全身3枚という下記の23枚で、第2弾のLoRA作成に挑みました。

学習時の画像につけるキャプションは、
顔だけのものが全て:ai_model_v1, close-up
上半身のものが全て:ai_model_v1, upper body
全身のものが全て:ai_model_v1, full body
とシンプルにしています。(第2弾なのでv2とした方が分かりやすいんでしょうが、今シリーズの完成までを、大きな意味でのv1と考えています)
そのほかの条件などは、第1弾と同じです。
まずは、顔の出力。
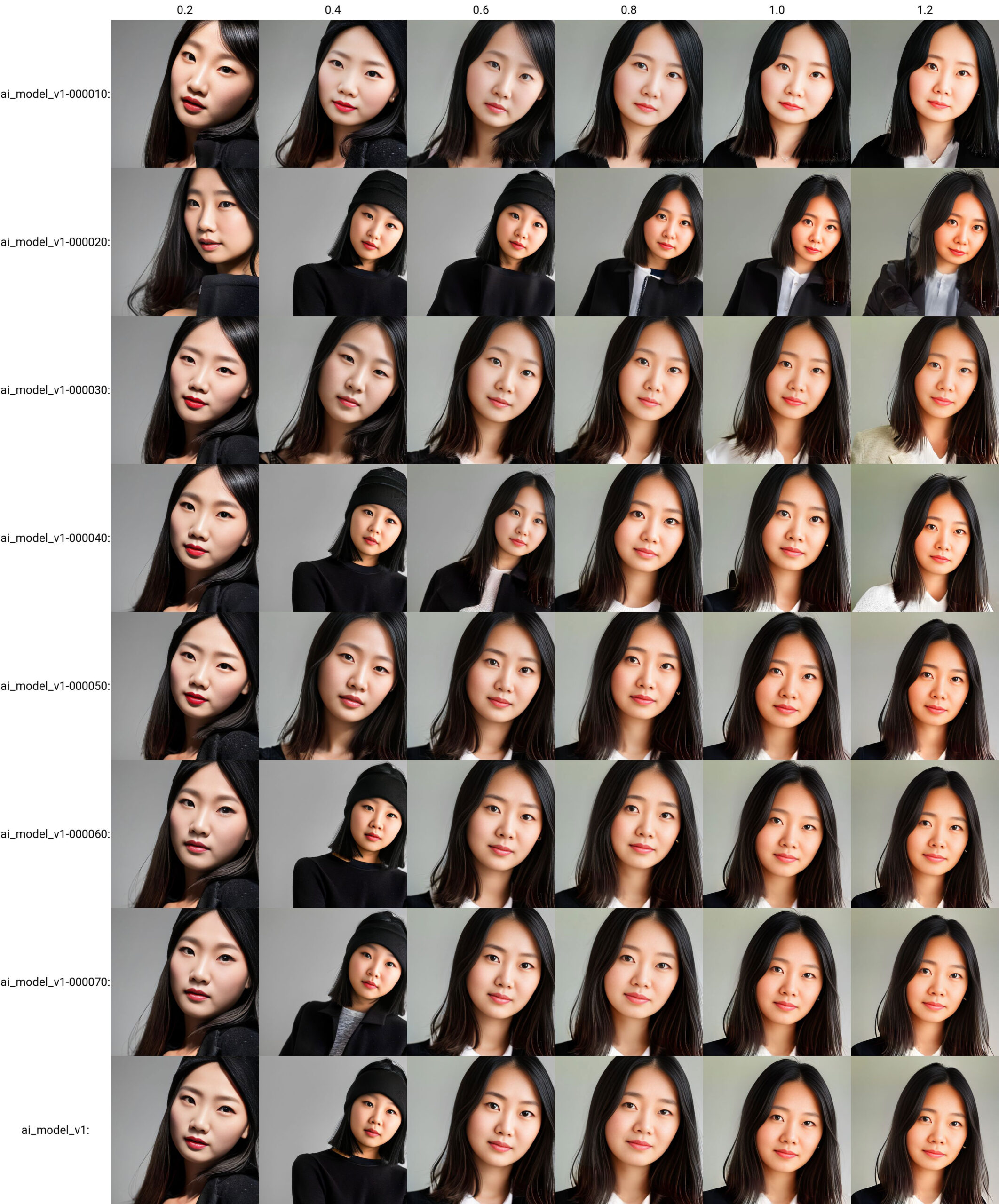
学習素材が多い=学習するStep数が増えていることから、第1弾よりも顔の固定(同一人化)が進んできているように思います。
まぁまぁ、想定通り、という感じでしょうか。先ほどと同じようにepochの10、20と、weightの0.2~0.6とをカットして、上半身を出してみます。

第1弾と違って、全て上半身が出力されました。が、逆にweightが高いものは、upper bodyというキャプションに引っ張られて、背景まで反映されてしまってますね。
というように、顔アップは顔アップ(close-up)のキャプション入りのものが、上半身は上半身(upper body)のキャプション入りのものが優先されるのかな、という感じですね。
では、全身は?ということで。

第1弾よりは、遥かに良い結果になったと思います。全身(full body)の構図が膝より上になっているのは、やっぱり学習時の画像とキャプションが影響しているんでしょうね。
とはいえその全身も、LoRAのweightが弱め(0.8)のものと、そもそもの学習が弱め(epoch 40)あたりまで。それより学習やweightが高いものは、学習素材のある上半身までが精いっぱいとなるようです。(学習素材の胸部よりは少し下まで出てますけどね)
ところが、です。
既にお気付きかとは思いますが、「顔の傾きが、素材と同じ」なんです。
顔アップなど、特に顕著ですよね。
1枚だけを見ると、さほど違和感はないんですが、全部をグリッドで見ると、気持ち悪いくらいにシンクロしてます。
これ、何とかしたいですよね。なんとかできるのか…。それは次回に、ということで。。
参考として記載していたプロンプトに、肝心の
lora:
のワードが抜けていました。
正しくは、このように、 lora: が無いと、意味を成しません。
<lora:ai_model_v1-000010:0.2>,ai_model_v1,
お詫びして訂正いたします。
顔の傾き(クセ)を改善すべく、さらなる学習素材を用意して改善に挑んだ話がこちらになります。
併せてご覧ください。
