
使えるLoRAを作り出す ~ 画像生成AI ⑤

ローカルPC上で画像を生成する Stable Diffusion を使って生成された画像を基として、kohya_ssによる学習を行い LoRA を作成することで安定した顔が表示されるようになったものの、元画像のクセが強すぎて困ったところまでが、前回の記事となります。

画像生成のための Stable Diffusion の環境を作成するところから(このシリーズの初回)は、こちらをご覧ください。
本記事に掲載している人物画像は、すべて生成AIにより作成したものであり、特定の実在人物をモデルにしたものではありません。
プロンプトでクセを補正?
たった1枚の画像からLoRAを作成しようとする計画ですから、元画像に引っ張られるのはある程度覚悟していましたが、顔の傾きまで固定化されてしまう、というのは、さすがにちょっと困ったところです。
再確認の意味で、このLoRAを使用して、いくつか生成してみましょう。
使用するLoRAは、なんとなく全身も行けるかな、という ai_model_v1-000040 で、効き・重み(weight)は、顔が変わらない 1.0 を使用することにします。
prompt
<ai_model_v1-000040:1.0>,ai_model_v1,
full body,
looking at camera,
soft daylight, realistic photo, high detail,
casual clothes,
in the city
negative prompt
worst quality, low quality, lowres, jpeg artifacts, blurry,
extra digits, fewer digits, bad hands, bad anatomy, deformed,
multiple faces, duplicate, extra limb, long neck
全身に近くなるほど、顔が派手に崩壊するので、まともに見えるものをピックアップしています。


悪くはないですけど、やっぱり、顔の傾きは同じですよね。
では、生成時のプロンプトでどれくらい変わるのか、ということで、この下向き加減の顔を上に向けてみよう、と、
prompt
<ai_model_v1-000040:1.0>,ai_model_v1,
full body,
looking at camera, looking up,
(以下略)
と追加。

何も変わらず。。
プロンプトの重みを徐々に増やしていって、
prompt
<ai_model_v1-000040:1.0>,ai_model_v1,
full body,
looking at camera, (looking up:2.4),
(以下略)
括弧を一つ増やすと、重みが1.1倍となるようですが、コロンを付けて数値を書くと、その数値が重みとなります。なので、2.4倍で見上げさせると…

確かにね。見上げましたね。。
いや、そうじゃなくて…。
でも、この角度からなら、真っすぐにも見えるんですよね。面白いものです。というか、どこまでこの角度にこだわるんだ…という感じですけど。
見上げる、じゃなくて、首を傾げる方向なのかな?と思って、今度は、追加した部分をこのように書き換え。画像の人物がこちらを向いて左(画面上の右)ではなく、画像上の左を向いてもらう、という意図です。
(tilt head to the left:2.0),それでも全然変わらなかったんですが、13枚目に出たのが、

ん?体全体が5時25分くらいの傾きになってますけど。。
それでも、顔は画面に対して真っすぐになったようです。とはいえ、13枚目でようやく1枚ですからね。しかも、身体と顔の傾き比率は同じ、という、問題を残してます。
目論見としては、顔がまっすぐに向いた画像を基にして、新たなLoRAを作成する、ということをやってみようと考えています。
そのためには顔をアップにしたものも欲しいのですが、epoch違いのLoRAや、weightを変えたりしたものの、顔がアップだと、全く傾き補正が効かないんですね。現在のLoRAの学習素材は、顔のアップ10枚すべてが同じ傾きですからね。そりゃ固着しますよね。
出なければ作っちゃえ
というわけで、頭の傾きのない、顔がアップの画像はプロンプトだけでは生成が難しい、ということからimg2imgも使用してみましたが、結局のところ、傾きが収まるまで Denoising strength を増やしていくと、確かに傾きの無い画像はできたんですが、顔は全くの別人になっていました。
しかも、LoRAの効きがどんどん弱くなるので、西洋人化していくんですね。
なので。
Photoshopで回転させます。
え?という解決方法ですが、最も手軽な「傾き補正」です。
元画像を表示し、「レイヤーを自由に回転」で、顔が真っすぐになるような角度を指定してそれを保存します。
それだけでは「全く同じ画像」となりますので、生成したJPEG画像をimg2imgで、プロンプトに
sharpだとか、
smileだとかで、微妙な風合いを変えた画像を生成します。

こんな感じですね。回転させただけなので、向かって右側の肩が上がってますが、これは仕方ないですね。
そのあと、上半身バージョンも作成。こちらは、衣装の固定化を防ぐために、img2imgでバリエーションを増やします。
前回に作成した画像も使用して、第3弾のLoRA作成に使用する画像がこれらの23枚。

学習時の画像につけるキャプションは、前回同様、
顔だけのものが全て:ai_model_v1, close-up
上半身のものが全て:ai_model_v1, upper body
全身のものが全て:ai_model_v1, full body
です。
出力時の設定も前回までと同様です。
まずは、顔の出力。

なんで、素材に元の写真を入れちゃったの…?という結果ですかね。。
続いては、前回までと同じようにepochの10、20と、weightの0.2~0.6とをカットして、上半身を出してみます。

seedを同じ123456789で実施すると、前回もそうでしたが、画面右端に寄って左腕が隠れてしまうため、seed値には123123123という値を使用しました。
前回(第2弾)は、右端に寄るのが出力全体の半数以下だったのでそのまま使用しましたが、今回は全部。
しかも、背景を指定していないので、ある意味、プロンプトへの忠実さが増しているような感じがしますね。それに、epoch:30の首の傾きがかなり抑えられているような感じがします。ここは、あとで深堀しましょう。
最後に全身。

首の傾きはともかく、full bodyというプロンプトの効きは、こちらでも前回よりも強まっている感じがします。
第4弾のLoRA作成へ
結局のところ、学習素材の半数以上が、首の傾いた画像なので、こうなってしまうのは致し方なし、ですかね。
とはいえ、これらは固定値のSeedを使用しているため、と言えるかもしれないので、ランダムの値(-1)で、確認してみたいと思います。
重み(weight)が1でepochが40以上なら安定して同じ顔が出せそうなので、epoch60のLoRAを重み1.0で確認。プロンプトは顔アップのものをそのまま使用しています。
Batch count を 6 にして、同じ設定で Seed違いのものを6枚出力。

プロンプトに傾きに関するワードは一切追加していないんですが、6枚中4枚、2/3が、ほぼ真っすぐな顔になっています。
学習素材の比率なら、10/23なので、この理由はわかりません。というか、何回やっても 2/3 というわけではないので、たまたまの要素が強いんですけどね。
それでも、第4弾LoRAのための素材を作成する上では、無駄なく十分な比率だと思います。
というわけで、プロンプトを少しずつ変化させて、顔の表情(目元、口元の状態など)をわずかに変化させながら、顔中心の画像を10枚、上半身の画像を10枚、全身(というキャプションですが、腰のあたりより上部)の画像を10枚用意しました。
敢えてつま先まで含む全身を用意しなかったのは、どのみち、SD1.5で最適な512×512では、全身を表示させると顔は非常に小さいために個性を出しにくく、画像を生成するにしても全身を表示させることは無いかな、と。そこに注力するのは、一旦置いておきたい、と思います。

今回は、ほぼ頭がまっすぐに向いたものだけを用意しました。表情は、ほぼ同じですけどね。
出力の設定は、これまで同様。まずは、顔から。
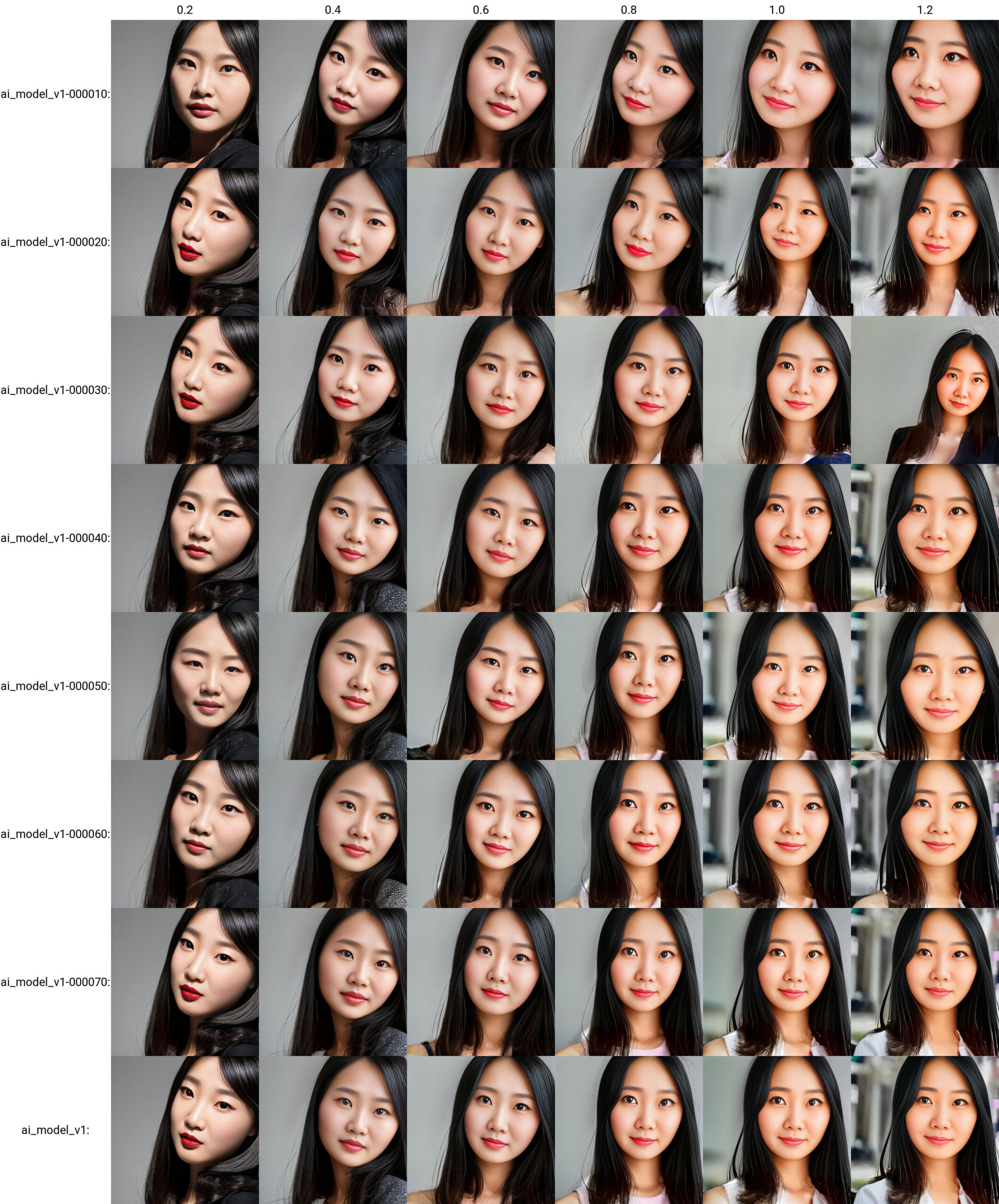
おや?
学習が進むほど(epochが増えるほど)、効き目が強くなるほど(weightが増えるほど)、顔の傾きが無くなっています。これって、このSeed(123456789)が、顔を傾けるものだったの??
いや、そうではなかったですね。念のため、同じプロンプトで、LoRAの設定とトリガーワードを削除(要は、1行目を削除)すると、

え?誰?
確かに、portrait と書いただけで、男性とも女性とも書いてなかったですよね。LoRAの力は0.2の効き目でも非常に大きい、ということですね。そういうことが改めて分かった気がします。
なんか期待が持てそうなので、引き続き上半身の画像を出力。範囲は前回までと同様です。seed値には第3弾と同じく、123123123を使用しました。

頭部と肩から下の比率に若干違和感を覚えるものもありますが、概ね期待通りの結果となった気がします。
ここまで順調なので、ちょっと怖いですが、最後に全身を。といっても、期待する全身は学習時の通り、腰より上あたりが出れば十分かと思ってます(それなら、上半身でもいい結果となってますが、念のため、です)。

意外にも学習が進み切っていないepoch50で、強い効きがありましたが、概ね想定通りという感じですね。
ポーズが気になるので、LoRAなしで確認してみると、ちょっと身体をくねらせたような画像となったので、Seed(12341234)依存だったようです。なので、別のSeed(23452345)でも確認。

顔・上半身・全身(腰より上)と、weightが1を超えない程度では、プロンプト通りになったのではないかと思います。
最適なLoRA選びの最終判断
顔のを見ても、上半身のを見ても、全身のを見ても、「これだ!」というLoRAが見えてこないので、最終チェックとして、次のような設定値とプロンプトを用意しました。
Sampler:DPM++ 2M Karras
Steps:28
CFG:6
Resolution:512×512
Batch:1
Hires.fix:OFF
共通で使用するネガティブプロンプトがこちら。
negative prompt
(worst quality:2), (low quality:2), (normal quality:2),
lowres, blurry, jpeg artifacts,
extra fingers, mutated hands, bad hands,
bad anatomy, bad proportions,
extra limbs, malformed limbs,
text, watermark, logo
指定ポーズへの追随確認(腕上げ)
まずは、第1ラウンド。
プロンプトで指定した指示が、どの程度反映されるか、の判定です。
prompt
<lora:ai_model_v1-000020:0.4>, ai_model_v1,
1girl, solo, upper body,
looking at viewer,
big smile,
hand raised,
simple background
が、これは苦労しました。というのが、そもそも、LoRAを使用していなくてもプロンプトに従わないSeed値がある、という事実です。なので、まずはLoRA指定なしで、Seedを -1 にして複数枚生成し、よく効いてそうなSeed値でテストをする、という必要がありそうです。
特定のSeed値を用いて、epoch20~80(枝番なし)を、weight 0.4~1.0(0.2刻み)で生成します。
その結果がこちら。

weight が低い方がポーズとしては、プロンプトへの順応性が高いんですが、顔も違ってくる、というトレードオフですね。それでも、高さは違えど、全員手を上げています。
ちなみに、Seedを123456にすると、こんな感じになります。

学習が進んだもの(epoch60以上)だと腕が上がりにくい(学習時のポーズが強く効く)傾向があるようですが、weightが低い方が上がっていないところもあるので、Seedによる差なのかな、とも思います。
腕組み
第2ラウンドは、腕組みでの生成確認です。
prompt
<lora:ai_model_v1-000020:0.4>, ai_model_v1,
1girl, solo, upper body,
looking at viewer,
big smile,
arms crossed,
simple background

事前に確認したSeedを使用したため、意外にも、オールクリアでした。細かな描画に難あり、というのはありますが、構図としてはプロンプトが効いています。
学習素材に腕を組んだものはありませんから、腕上げにしても、腕組みにしても、全クリアとは、ちょっと意外な結果でしたね。
腰に手
最後に、腰に手を当てたポーズ。
prompt
<lora:ai_model_v1-000020:0.4>, ai_model_v1,
1girl, solo, upper body, from waist up,
looking at viewer,
big smile,
hand on hip,
simple background

これも、適切なSeedを最初に選定したこともあって、パーフェクトでした。ちょっと弱いところとか、手のひらのバランスが悪いのとかもありますが、概ね良好です。
最終ジャッジは?
…で。
結局どれがいいのかは「わかりません。。」
明確な差が出てくるかと思ったんですが、「出るものは出る、出ないものは出ない」という結論でした。「出ない」というのは、そもそも学習データに無い、45度、顔や身体を傾けたポーズで、これは、どれもがNGでした。
なので、big smile が一番効いてそうな枝番なし(80)がベストなのか?と。頭と身体とのバランスも、どのテストでも安定してましたし。
もう少し、差が出るテストを考えてみます。。
というわけで、「Seed次第で(Seedの当たり外れを見極めれば)」いろいろなポーズが出そうなことも副産物として得られましたし、第4弾のLoRAは、成功、ということで終わりたいと思います。
ただ、先に書いた、身体を傾けたり、回転させたり、いろいろな表情を出したり、とかは未調査ですので、そのあたりは、さらなる確認が必要ですね。
今回の締めくくりとして、こんな画像を出してみました。サイズは640×360です。
prompt
<lora:ai_model_v1:1.0>, ai_model_v1,
1girl, solo, upper body,
looking at viewer,
Woman working on a computer,
at office
複数枚出して、ベストな1枚です。顔の傾きがちょっと入ってますが、「何らかの作業中」の様子なら、これもアリかな、と。

プロンプトの「computer」 はどこに?とは聞かないで。。
学習データには無い顔の向き(回転方向)を出せないか、と、SDXL化に挑んでみました。SD1.5よりも生成画像の自由度が増しましたね。こちらも併せてご覧ください。

Stable Diffusionの環境構築からLoRA作成、SDXLでの検証までの記事一覧は、以下のまとめページに整理しています。
