
SDXLでのLoRA作成 ~ 画像生成AI ⑥

ローカルPC上で画像を生成する Stable Diffusion を使って生成した、たった1枚の画像から、kohya_ss による学習を重ねて、まぁまぁ使えるかな、というSD1.5のLoRAを作成できたところが、前回の記事となります。

画像生成のための Stable Diffusion の環境を作成するところから(このシリーズの初回)は、こちらをご覧ください。
本記事に掲載している人物画像は、すべて生成AIにより作成したものであり、特定の実在人物をモデルにしたものではありません。
LoRAのSDXL化を試みる
もともとは、Stable Diffusion のベースとなるSD1.5でのLoRA作成をこのシリーズのゴールにしようかと考えていたんですが、このテーマとは別にいろいろと試していると、SDXLでの「自由度」がかなり魅力的で、今回のSDXL化までを一つのシリーズに含め、一旦の完結編としたいと考えるようになりました。
SDXL(Stable Diffusion XL)は、Stable Diffusion 1.5 (SD1.5)の流れを汲んだ、より高精細で自然な画像を生成しやすい画像生成モデルとなります。
SD1.5 世代より内部のモデル規模が大きくなり、複数のテキストエンコーダやより大きなUNetを使うことで、プロンプトへの追従性や画像全体のまとまり、細部表現の向上が図られている、ということのようです。
なので、求められるハード要件も少し上がってしまうんですが、RTX 2060 SUPER ( VRAM 8GB ) でも並行処理なんかをしなければ生成可能でしたし、ローカルで画像生成しようと志す方なら、それほど敷居が高いものでもないのかな、と思います。
で、今回のSDXL化の狙いは、「高画質」ではなく、「自然な画像を生成しやすい」というメリットを得るのが目的です。
1枚の画像を基に学習するので顔の向きや顔の傾きが固定化される、というSD1.5を使用する上でのこのシリーズでの一貫した悩みから、「ひょっとしたら解放されるのでは?」という期待を込めた導入となります。
それでは、さっそく準備していきましょう。
モデルを取得する
これまで使用してきたのは、v1-5-pruned-emaonly.safetensors という SD1.5 の基礎となるモデルです。
今回は、SDXLですので、sd_xl_base_1.0.safetensors を使用します。
SD1.5よりも、ベースと分かりやすいネーミングですよね。
この sd_xl_base_1.0.safetensors はSDXLのベースモデルで、必要に応じて、仕上げ用の Refiner モデル( 低ノイズ段階で細部を整える専用モデル )と組み合わせて使用するそうですが、今回はベースモデルのみを使用することにします。そのあたりは、今後、追っていきたいですね。
モデルのファイル取得は、SD1.5のときと同様、Hugging Faceから。
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0 にアクセスします。
タブ(上記画面で表示中なのは[Model card])を、その隣の[Files and versions]に移動します。
ファイル一覧が現れますので、その下の方にある sd_xl_base_1.0.safetensors の行、画面中ほどのダウンロードアイコン[↓]をクリックして、ダウンロードします。
取得したファイルを、
stable-diffusion-webui
└─ models
└─ Stable-diffusion
└─ sd_xl_base_1.0.safetensors
└─ v1-5-pruned-emaonly.safetensorsに格納します。
学習データの準備
続いては、学習用の画像データの準備です。
基本的には、SD1.5の最終版で使用したデータ(顔中心が10枚、上半身中心のもの10枚前後と、腰のあたりまでのを含めて総数26枚)を使用します。
が、これらはSD1.5用に、512×512のサイズで作成しています。
せっかくSDXL化するので、SDXLの基本サイズである1024×1024で学習したいところですよね。なので、リサイズしてみることにしました。
もちろん、512×512の画像データでも直接SDXLのLoRA作成は可能なのですが、同じ作成するならちょっとでもいいものを、ということですね。
Photoshopでの拡大でもいいんですが、AUTOMATIC1111で出来ることはやってみたいので、Extrasによる拡大を試してみました。
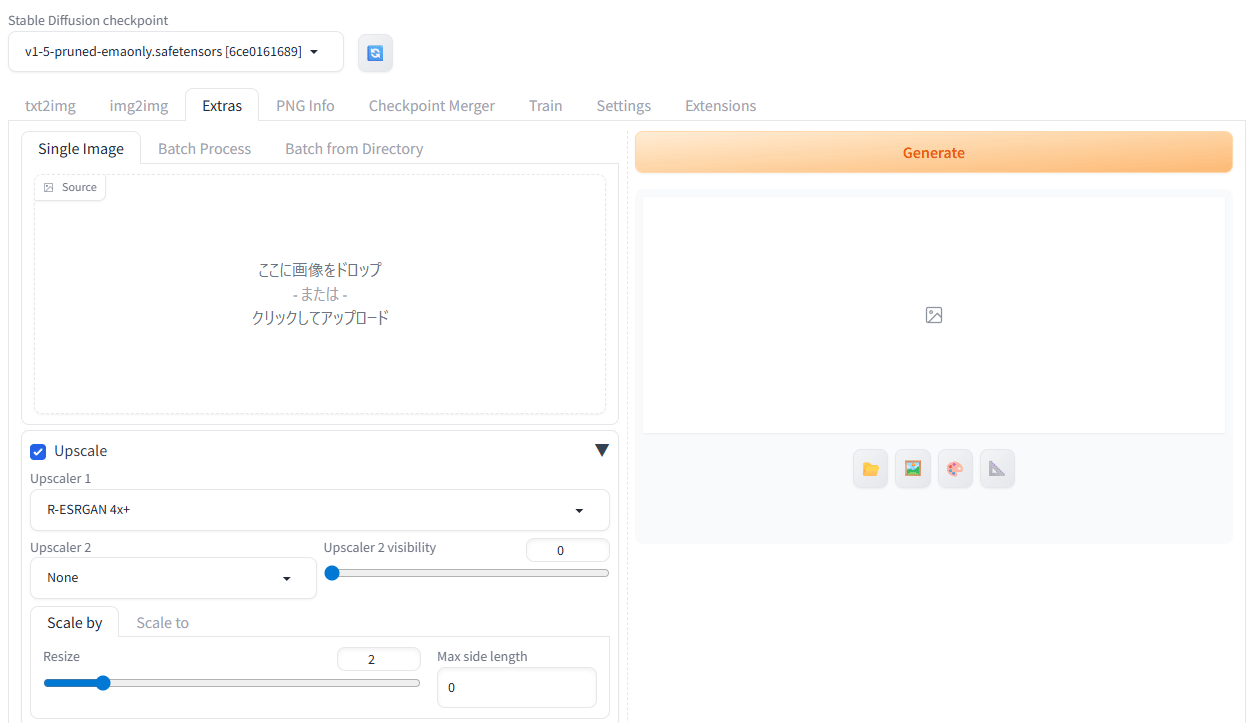
タブを、txt2img ではなく、 Extras に移します。
Upscaleにはあらかじめチェックが入っていると思いますので、Upscaler 1 に、「R-ESRGAN 4x+」を指定します。で、512×512から1024×1024なので、Scale by タブの Resize を 2 に設定します。
1枚ずつ変換してもいいんですが、合計26枚なので、ディレクトリ単位で一気に変換。
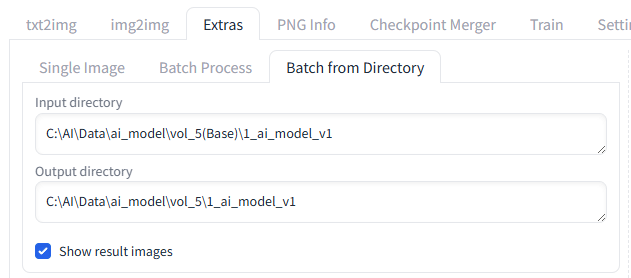
こんな風に、Batch from Directory を使用して、入力・出力のディレクトリを設定すれば、一気に変換できます。
ちなみに、Extrasではなく、img2imgでもResize機能があるので拡大はできます。
これらの違いは、一言で表せば、
Extrasでの拡大
= 画像をそのまま拡大・補正する処理
img2imgでの拡大
= 画像を元にしつつ、Stable Diffusionで描き直しながら拡大する処理
のような感じでしょうか。
img2imgの方は、denoising strength に応じて元画像へノイズを加えて再生成するので、上手く働けば期待以上の拡大画像になりますが、下手すれば別物になる可能性もあります。
その点、Extrasは ESRGAN系のアップスケーラで画素数を増やす処理になりますので、元画像の構図や顔立ち等を大きく変えずに解像度を上げることができます。
どんな感じになるのか、例示してみると、こんな感じ。

左がExtrasで拡大したもの。右がそのままの画像を「単純に2倍」して画像サイズを合わせたものを並べています。
髪の生え際が一目瞭然でしょうか。目もくっきりしてますよね。
というわけで、Extrasで1024×1024に拡大した26枚を用意して、LoRA作成に挑みました。
SDXLでのLoRA作成
SDXLでも、使用するのは、kohya_ssです。
SD1.5のときと変えないといけないのは、もちろん、「Model」。
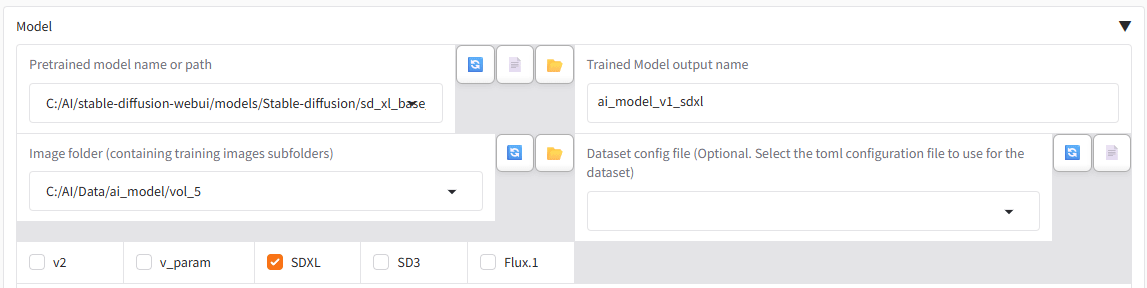
「Pretrained model name or path」に、先ほどダウンロードして格納した sd_xl_base_1.0.safetensors を指定します。
SDXL系のモデルを指定すると、下段の「SDXL」のチェックが自動的に付きます。
他には、必須と言える項目はないんですが、「Parameters」タブの、解像度は変更しておかないと、せっかくの拡大作業の意味がなくなりますね。
Max resolutionを 1024,1024 にしました。
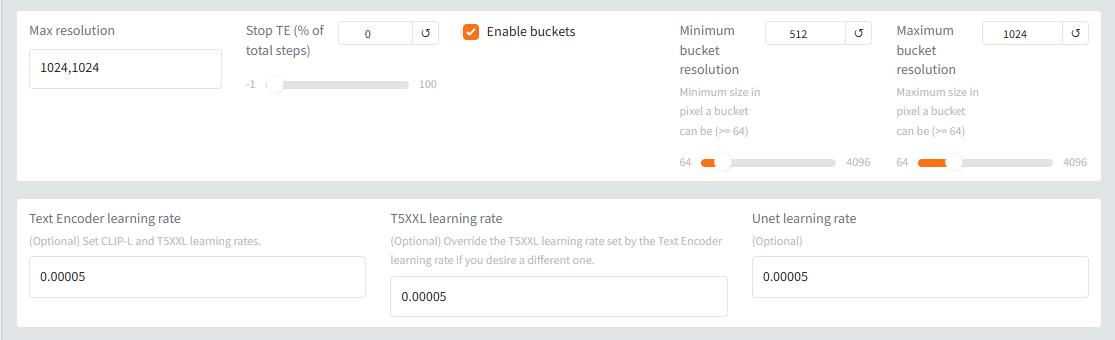
こんな感じでしょうか。
では、「Start training」!
待つことしばし。というか、じっと見ながら待ったことは無いですけどね。それが裏目に出るとは…。
SDXL化の成果は?
さすがに、SD1.5と比べると、格段に時間が伸びます。
もっと縮める方法はあるんでしょうが、現状の設定だと、GPUにRTX5070Ti(16GB)を使用して、バッチサイズが2 ( = 意図的に2で抑えています)、学習ステップ数が1,040 ( 26枚 x epoch数 80 / batch 2 )で約40分です。
ai_model_v1_sdxl-000010.safetensors から ai_model_v1_sdxl-000070.safetensors と ai_model_v1_sdxl.safetensors が出来たところで、テスト用のフォルダにこの8ファイルを格納します。
stable-diffusion-webui
└─ models
└─ Lora
└─ Test
└─ ai_model_v1_sdxl-000010.safetensors ~それから AUTOMATIC1111 での操作に移ります。
何はさておき、チェックポイントの変更を。
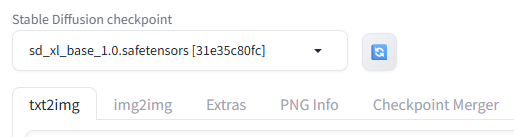
これがSD1.5のままなら、LoRAを作成しても、SDXLとしての画像生成ができません。
「LoRA」タブで、LoRAファイルを格納したフォルダを指定します。
チェックポイントを変更しているので、SD1.5用のLoRAファイルは見えなくなっています。さすがですね。で、もし、このとき、SDXL用のLoRAファイルも見えていないようなら、AUTOMATIC1111が認識できていない、ということですから(AUTOMATIC1111を立ち上げたまま、LoRAファイルを追加するとこうなります)、この右端にある、くるっと回るアイコンをクリックして、再読み込みを行います。

お試しで1枚、作成してみたいところですが、「X/Y/Z plot」で、比較用の生成を一気にやってみたいと思います。
前回のテーマで、「最適なLoRA選びの最終判断」として使用したプロンプトを使用します。
再掲しておきましょう。
まずは、共通で使用するネガティブプロンプトから。
negative prompt
(worst quality:2), (low quality:2), (normal quality:2),
lowres, blurry, jpeg artifacts,
extra fingers, mutated hands, bad hands,
bad anatomy, bad proportions,
extra limbs, malformed limbs,
text, watermark, logo
プロンプトは、SDXL用に、LoRA適用部分を変更しています。
prompt
<lora:ai_model_sdxl_v1-000020:0.4>, ai_model_sdxl_v1,
1girl, solo, upper body,
looking at viewer,
big smile,
hand raised,
simple background
その他のパラメータは、
Sampler:DPM++ 2M Karras
Steps:28
CFG:6
Resolution:1024×1024
Batch:1
Hires.fix:OFF
としました。サイズを、SDXLに最適とされる 1024×1024に拡大しています。変更点はそれくらいですね。
というわけで、「X/Y/Z plot」には、前回同様、epoch20~80(枝番なし)と weight 0.4~1.0(0.2刻み)を設定して生成しました。
Seedには、固定値の 123456 を使用して、生成開始。
SDXLでの28枚の画像生成に要した時間は4分13秒。1枚当たりおよそ9秒といったところでしょうか。
で、その成果は…。

なんだこりゃ?です。。
LoRAが全く効いていないですね。
LoRAファイルが生成されているのに、LoRAとして効いていないとはどういうこと?
と、kohya_ssの出力内容を見てみると、
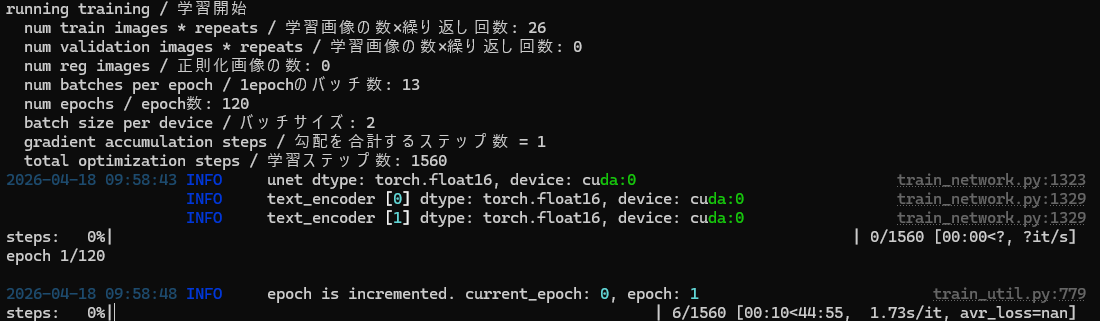
stepごとの成果の 右端、avr_loss の値が、 nan となっています。
LoRA生成中の出力内容をチェックしていれば、途中で気づくこともできたんでしょうけどね。。
avr_loss とは、学習時のその時点までの平均(average) 損失値(loss) のことで、値が小さいほど「学習データに合っている、収束してきている」という値になります。
この値が nan になるというのは、計算途上で計算結果が「普通の実数では表せない値」になって壊れている、ということのようです。とはいえ、そのまま計算が完遂するというのも変な感じですが、stepを重ねる中で、一時的にnanとなった後に復活することもあるということなんでしょうかね。そうでなければ、そこで止めてしまう方が分かりやすいと思いますし。
一般には、学習率が高すぎる、とか、精度まわりの問題(fp16などの設定がモデルやGPUとの相性)とか、もちろん、学習素材そのものに問題があるということも考えられるようです。
avr_loss = nan の解消に向けて
とはいえ、実は、これまでLoRAでのSDXLの学習を旧機(RTX 2060 SUPER)でもやってきた実績があり、できないことは無い、と思っています。
ところが、なんだかんだとハマりましたね。
前回の記事から早々に続編を出そうと思っていたのに、一向に改善できない( avr_loss = nan が解消しない)んです。
同じ kohya_ss の環境で、実績のあるデータとパラメータとを組み合わせると SDXLのLoRAがきちんと生成され、今回の学習データとパラメータとでは nan のまま。
生成実績のある画像データとパラメータに、少しずつ変更を加えていったら何かわかるかも、と思って試行錯誤していると、実績があるはずのデータとパラメータでも、nanが出てくるという、なんだかわけのわからない状態に陥って、なかば諦め状態になりつつあったんです。
結局、主因としては「SDXL Specific Parameters」の「No half VAE」にチェックが入っているか、入っていないか、ということのようでした。

これにチェックが入れる必要がありました。
この項目の説明として、
Disable the half-precision (mixed-precision) VAE. VAE for SDXL seems to produce NaNs in some cases. This option is useful to avoid the NaNs.
SDXLのVAEは NaNを生じることがある、このオプションはNaNの回避に役立つ、って書いてありますからね。
でも、これによって解決しなかったから厄介なんです。
というのも、nanが出た状態のまま、「No half VAE」にチェックを入れて再生成しても、同じくnanが出ます。この原因が、学習素材データのフォルダに生成される npz ファイルだったんですね。
npzファイルは、画像ファイルに対して1つ生成される中間データのキャッシュなんですが、ここにhalf VAEの有無に影響を及ぼす情報が入っているとは思ってもなかったので、逐一消去してなかったんです。
なので、No half VAEにチェックを入れずに nan が出た状態で、このnpzファイルを消去しないまま No half VAEにチェックを入れても、次回生成ではやっぱりnanが出る、と。
なので「この No half VAEへのチェックは関係ない」と、早いうちに思い込んでしまった、というミスですね。
再生成したLoRAで性能チェック
指定ポーズへの追随確認(腕上げ)
では、期待を込めてもう一度。

SD1.5よりもSDXLの方が、epoch数を増やした方が良さそうという話もありますので、今回のLoRA生成には、26枚x120stepで回してみました。26枚x10stepごとに途中のLoRAファイルを保存しますので、都合12ファイルをX/Y/Z plot の対象に入れてますので(効果が薄いと思われる 初回のai_model_sdxl_v1-000010 は省略)、合計で44枚の生成となりました。6分44秒なので、1枚当たり平均9.2秒です。
1枚1枚の顔の造りが、さすがはSDXLできめ細かくなっているのが分かります。
結果の方はというと、全般に「手を上げる」というプロンプトが効いているようです。肝心の顔の方も、重み(weight)が高ければ、step数が低くても特徴が良く出ていますね。
ただ、重みが1になると、ちょっと頭部と身体とのバランスがおかしく見えるものもあって、この時点ではどれがベスト、と決めるのは難しいですね。
腕組み
第2ラウンドは、前回と同じく腕組みでの生成確認です。
プロンプトは、こちら。
prompt
<lora:ai_model_sdxl_v1-000020:0.4>, ai_model_sdxl_v1,
1girl, solo, upper body,
looking at viewer,
big smile,
arms crossed,
simple background

SD1.5のときと同じく、プロンプトだけでは簡単に腕を組んでくれなかったので、ランダムにいくつか生成し、腕を組みやすいSeedを選んで使用しました。
これだけを見ると、weightを1にするのは効き過ぎになってしまうのかな、という感じですね。それと、80以上は変化がほとんどなく、学習の飽和状態になっているのかな、という感じも受けます。
腰に手
最後に、腰に手を当てたポーズ。
prompt
<lora:ai_model_sdxl_v1-000020:0.4>, ai_model_sdxl_v1,
1girl, solo, upper body, from waist up,
looking at viewer,
big smile,
hand on hip,
simple background

今回も、選んだSeedを用いたので、全般にプロンプト通り、腰に手を当てた画像になっています。
こちらの印象も、腕組みの時と同様です。weightが1だと学習に引っ張られ過ぎになりますね。それと、80以上だと変化がない、というのも同じです。
別の観点での確認
SDXL化して、やってみたかったのが、学習した画像にはない角度への挑戦です。
SD1.5では、プロンプトで斜め横を向かせようとしても、ほぼ不可能という状況でした。
prompt
<lora:ai_model_sdxl_v1-000020:0.4>, ai_model_sdxl_v1,
young woman, solo, portrait,
three-quarter view,
gentle smile,
plain background,
photo, realistic, natural lighting
これで得られたのがこちら。これまでの例から、90以上の変化が乏しいので90までと減らしています。逆に重みの方は1.0の使用が厳しそうなのと、0.8前後で細かな変化を見てみたいので、0.4 / 0.6 / 0.7 / 0.8 / 0.9 の5パターンとしました。

傾向としてはわかりやすい結果になったと思います。学習が深い方、重みが大きい方が「(学習が強く影響して)プロンプトが効きにくい」という感じですね。
epoch 80 の weight 0.7 が、顔の雰囲気を残したまま、斜めを向いたんじゃないでしょうか。

斜めの角度は、わずかですけどね。
参考として、同じプロンプト(LoRA指定のみ変更)で、SD1.5のLoRAで作成した画像を掲示します。

同程度の傾きが出るのは、weightが 0.4 のときくらいで、それ以外は正面です。辛うじて斜めになった画像も、LoRAの重みが低いため、「同一人」というには厳しいかな、という顔立ちですね。
話をSDXLに戻します。
SDXLのLoRA作成のために使用した画像データは、全て正面を向いたものでした。口の両端から顔の輪郭までの長さが、ほぼ同じですね。それが、ごく一部とはいえ、口の両端から輪郭までの長さが左右で明らかに違う、つまりは斜めを向いている画像を生成することができました。
やっぱり、当初の予想通り、SDXLの方がSD1.5よりも「自由度」が高そうです。
自由度を判断基準にしていいのかどうかは分かりませんが、顔の雰囲気も良く出ていますし、今回は、このepoch 80 の LoRAを採用したいと思います。
よく見ると、img2imgでの素材作成時の粗さがそのまま学習されてしまっていたりしますが、方向性としてはやりたいことが実現できたのかな、と思います。
Stable Diffusion の環境を構築するところから、SD1.5でのプロンプトによる画像生成、LoRAによる同一人物の生成、プロンプトによるポーズの変化、それをより実現するためのSDXL化と、一連の流れで進めて来ましたが、このシリーズは、一旦ここまでとしたいと思います。
とはいえ、画像生成に関しては、やってみたいことがまだまだありますので、新たなテーマを考えて、実施していきたいですね。
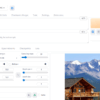
というわけで、締めくくりとして、このLoRAを使用して生成した画像を挙げてみたいと思います。
prompt
<lora:ai_model_sdxl_v1-000080:0.7> ai_model_sdxl_v1,
young woman, solo, upper body,
three-quarter view,
body turned slightly to the side,
face turned toward camera,
light smile,
outdoor hiking outfit, light jacket, trekking pants, backpack,
standing at a scenic viewpoint,
beautiful mountains and lodges in the background, blue sky,
travel photo, realistic, natural lighting
Stable Diffusion の環境を作成した1回目で生成したロッジに、ようやく辿り着いた、ということでしょうか。
画像生成の山はまだまだ高く、奥も深いですけどね。
生成の自由度が高いSDXL。それなら学習時の素材が少なくてもLoRAが作れるのでは?
と、実験してみたのがこちらです。
avr_loss=nanへの本来的な対応についても触れていますので、併せてご覧ください。

Stable Diffusionの環境構築からLoRA作成、SDXLでの検証までの記事一覧は、以下のまとめページに整理しています。
