
1枚の生成画像からSDXLのLoRA作成 ~ 画像生成AI実験メモ ①

ローカルPCに画像生成AIの環境を構築し、プロンプトで生成した1枚の人物画像から、SD1.5でのLoRA作成、次いでSDXLでのLoRAを作成することで、生成した人物を比較的自由な姿で新たな画像を生成できる状態にまでなりました。
この一連の流れを一つのテーマとして記載してきたのがこちらです。
今回からは、実験メモとして、それぞれの深掘りや、新たな発見を単発で書いていきたいと思います。
本記事に掲載している人物画像は、すべて生成AIにより作成したものであり、特定の実在人物をモデルにしたものではありません。
お手軽LoRA作成
その初回となる今回は、なんか遠回りした感のある「SDXLのLoRA作成」までの道のりを、もっとストレートにショートカットする方法を実践して書いてみたいと思います。
出発点は、SD1.5で生成した1枚の人物画像です。
もちろん、これをSDXLで新たに生成したものから始めてもいいのですが、ブログのキャラクターにするんだ、と始めてしまった以上、新たな人物像を創作するのも違う気がするので、あえて、第2回で作成した画像からスタートしてみたいと思います。
というわけで、SDXL版のLoRA(2代目)を作るわけですが、何はともあれ学習素材の作成から始めていきます。
用意したのはこれだけ?
今回の記事は、結論に至った手順を先に紹介したいと思います。行きつくまでに結構な遠回りをしたので、そのあたりは、そのうちに別記事で紹介したいと思います。なんせ、遠回りした内容を書くと、全然「お手軽」じゃなくなってしまいますので…。
第2回目にSD1.5で作成したこの画像。

SD1.5でのLoRA作成時には、「顔だけ」の素材で学習をしたら、プロンプトで上半身や全身と指定しても、顔のアップしか生成されない、という残念な結果となりました。言ってみれば「この顔のアップがLoRAの学習結果」みたいな感じですね。なので、顔以外の上半身を出そうとするとLoRAの重み(weight)を弱めるしかなく、そうすると、当然、顔も似なくなってきます。

ですが、SDXLは、学習に用いる画像を、きちんと「この顔の特徴がLoRAで学習すべき対象」と認識してくれるようで、例えば顔の輪郭や目鼻立ちは特徴として学習するけれど、素材の構図(顔のアップ)までは取り込まない、と。学習して欲しいことを学習してくれる、という感じですかね。
SD1.5のときに、苦しんだもう一つの問題、学習素材の画像が首を傾げたものだと、その傾きも特徴として学習してしまうという問題にも強いようです。顔の傾きまで学習して欲しいとは思わないですからね。

なので、用意するのは、「顔の各パーツが鮮明な(首を傾げたままの)顔アップの画像だけ」です。
まずは、Photoshopで顔の部分を切り出します。330×330という小さな画像になりました。

せっかくのSDXL。1024×1024のサイズで学習したいので、Extrasで拡大画像を生成します。前回にも書いた通り、Extrasでの拡大は、img2imgとは違い、ディテールはしっかり描きながらも、見た目の雰囲気は変えることなく画像が拡大されます。縦横3.1倍でも1024×1024サイズになるのですが、拡大後のサイズ指定で1024×1024とします。この方が簡単で確実ですね。
で、顔のアップ画像が1枚、出来ました。
以上
です。今回は、この1枚だけで学習してみます。(拡大した画像は、ほぼ同じなので掲載は省略します)
VAEの準備も
ベースモデルにこだわる必要がどこまであるか、ということではあると思うんですが、SD1.5もベースモデルで通しましたし、SDXLもベースモデルで作成するのが比較実験としては必要かな、と。
ただ、前回でも問題になった通り、kohya_ssでの学習(LoRA作成)時に「No half VAE」オプションをONにする必要がある、というのが引っかかっていたんです。まぁ、付けりゃ回避できるんだったらそれでいいんじゃない?とも言えますが、fp16では avr_loss=nan になるので fp32 で回避したという事実は確かで、計算精度を上げることで時間とVRAM使用量がわずかながらに増加するのを許容した、ということになります。
なので、本来的には fp16 のまま学習できればそれに越したことが無いのかな、ということで、それに対応したVAEを用意します。
VAEを指定すると「No half VAE」オプションをOFFにしても学習が出来た(avr_loss=nanにならなかった)というのも結果的に、ではあります。
VAE ( Variational AutoEncoder ) って何者?というのを詳しく説明できるほど理解が深いわけではないんですが、一言でいえば、Stable Diffusionで、「画像」と「latent」と呼ばれる「AIが扱う圧縮データ(≠画像データ)」とを相互変換する部品、ですかね。
そもそもlatentとは…となってくると画像生成AIの本質になるんでしょうが、ChatGPTが示した学習時の流れは、このようなものです。
学習画像
↓
VAE Encoder
↓
latent に変換
↓
そこへノイズを加える
↓
U-Net / Diffusion model がノイズを予測
↓
正解ノイズとの差分を見て LoRA の重みを更新まず画像をVAEでlatentに変換し、そのlatentに対してノイズを加えて、モデルが「このノイズをどう取り除けば元の画像に近づくか」を学習する、のだとか。なんか、わかったようなわからないような、ですが、WindowsOSの中身を知らなくてもパソコンは触れる、ハイブリッド機構の仕組みを知らなくても車は運転できる、というノリで続けましょう。
でも、これだけは覚えておかないといけないのは、VAEが変わると、学習画像から作られるlatentの内容が変わるので、細部の保持具合や、色・質感の表現などが変わる可能性がある、ということ。学習したLoRAを使用して生成される画像にもそのあたりの影響を与える、ということです。
というわけで、いつものように Hugging Face のサイトへ。そこから VAE をダウンロードします。
https://huggingface.co/madebyollin/sdxl-vae-fp16-fix にアクセス。
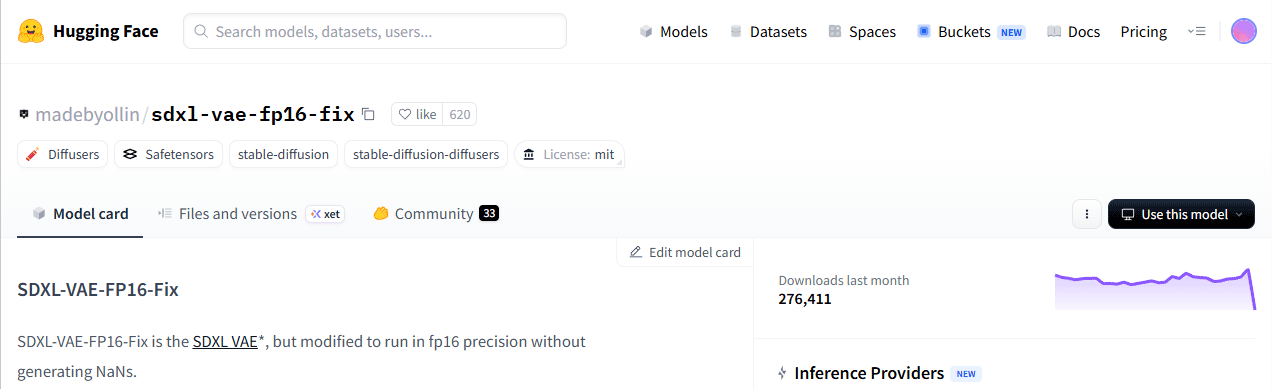
タブ(上記画面で表示中なのは[Model card])を、その隣の[Files and versions]に移動します。
※きちんと、「SDXL-VAE-FP16-Fix is the SDXL VAE, but modified to run in fp16 precision without generating NaNs.」と書かれてますね。NaNを出さずにfp16精度で実行できるように変更されています、と。
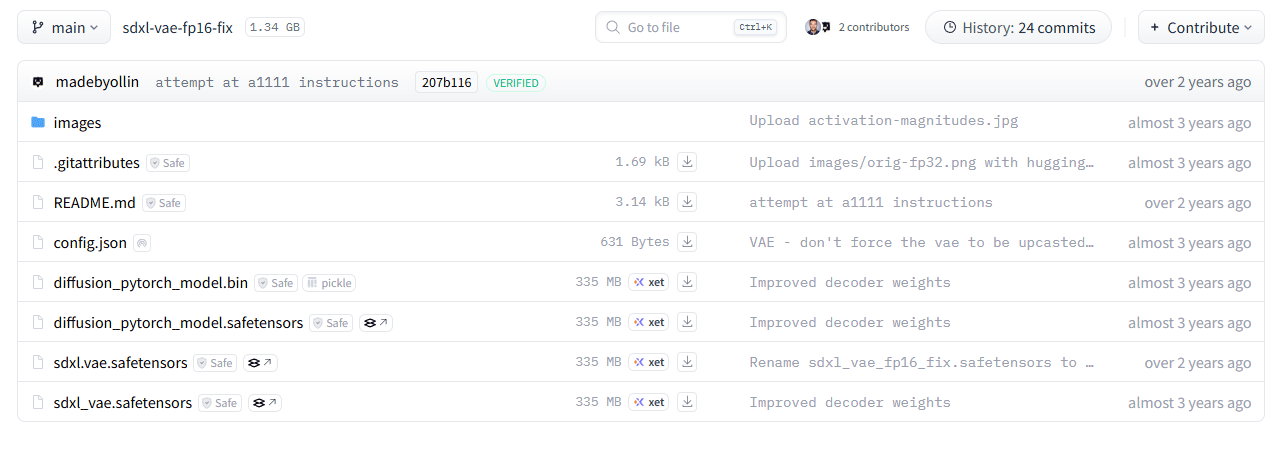
ファイル一覧が現れますので、その下の方にある sdxl_vae.safetensors の行、画面中ほどのダウンロードアイコン[↓]をクリックして、ダウンロードします。
取得したファイルを、
stable-diffusion-webui
└─ models
└─ VAE
└─ sdxl_vae.safetensorsに格納します。
kohya_ssでの学習
オプションに関しては、前回とほぼ同様です。変更したのは、VAEをダウンロードしてきたファイルに指定したのと、「No half VAE」のチェックを外したくらいですね。
VAEは、通常閉じられている「Adbanced」を開いたところにあります。画像は、ファイル指定後のものです。
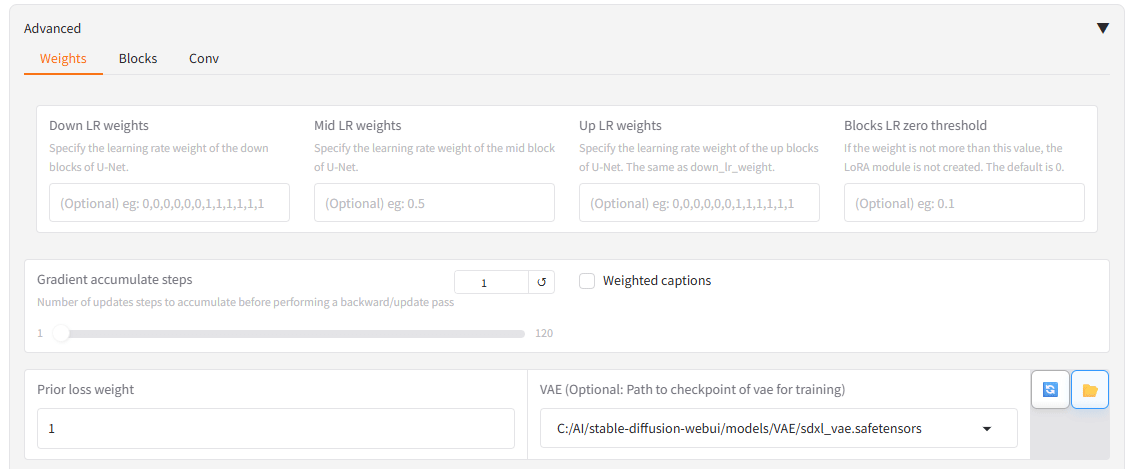
それともう一つの変更点、これも結果論ではあるんですが、epoch数をかなり増やしています。ここは最適解がまだ見つかっていないので、とりあえず200に。
epoch数が10ごとにファイルをLoRAファイルを生成する設定はそのままです。
各ファイル(…って言っても1枚なんで)のリピートも1のままですから、epochが200でも、総Step数は200にしかなりません。
epoch数を増やすと、使えないくらいに固着した学習結果になるんじゃないか、なんて思っていたんですが、そもそものStep数が非常に少ないので(学習素材30枚なら、epoch=80 でもStep数は2400になります)、過学習と言えるほどでも無いのかもしれません。それは、試してみてのお楽しみ、ですね。
Step数が少ないので、SDXLなのに5分ちょっとで終わりました(もちろん、所要時間は環境依存です)。
avr_loss = nan にならなかったのは、やっぱり VAE が効いてるんですね。
画像生成での確認
たった1枚での学習だと、どれくらいのepoch数のLoRAが最適なのかなんて判るはずもなく、とりあえず、生成された20個のファイルを全部判定対象としてみました。
使用したパラメータとプロンプトは基本的には前回と同じなんですが、Seed値に関しては、LoRAがなくても意図した(プロンプトが効いているように見える)画像が出力されたものを使用することにします。weightは、0.4から1.0まで、0.2刻みでを X/Y/Z plotに設定します。
腕上げ
まずは、腕を上げたポーズから。
プロンプト/ネガティブプロンプト/各種パラメータはこちらをご覧ください。

結果はこちら。

SDXLのベースモデルは、プロンプトに明示しないとアニメ寄りになるケースが多いように思います。このSeed値もそうでした。それでも面白いのが、LoRAの学習が徐々に高まる、epoch30あたりから写真っぽくなり、100を超えたあたりから本人らしくなってきます。
ただ、プロンプトで指示をした腕を上げるというポーズに関しては、LoRAのweightが弱いところと、なぜか(理由は不明)LoRAの学習が深いあたりで効くようになっています。
とはいえ、感動したのは、epochが200の強い学習が効いているはずのLoRAで、「顔が真っすぐ」ということです。

正直なところ、驚きましたね。たった1枚での学習でこうなるんだ、と。
顔のアップより広範囲な上半身の画像が生成できていますし、首の傾げも無いですよね。
腕組み
続いては腕組み。こちらもパラメータ等は前回と同じです。
腕上げでの生成状況からみて、epoch数は50から200とし、weightは中域からということで 0.7から1.0まで0.1刻みとしました。

こちらは、すべての画像で腕を組んだスタイルになりました。Seedによる違いなんでしょうかね。
こちらでもepoch数が100を超えるあたりから、本人らしさが出てきていると感じます。逆に150あたりからはあまり違いがなくなっているようにも見えますね。
腰に手
最後は、腰に手を当てたポーズ。

傾向としては、前述の2つと同じような感じです。が、weight = 1.0だと、epoch = 150 あたりから、学習素材の傾き感が出てきているように見えます。身体全体の傾きも含めて、Seed値に左右されているのもあるとは思いますけどね。
結論としては、weight = 1.0 を使用するならepochは100~140あたり、weightを下げるならもう少し学習したものでも可、というところでしょうか。
斜め横向き
前回もSDXLならではということで挑戦したのが、斜め横を向いた顔です。

weightが1だと、学習が進んだものだと正面向きになってきているようですが、前回と違って、身体全体が正面向きになったりだとかは無いですね。

epoch 180 の weight 0.9 でも、十分に斜めを向いたと言える顔になっていると思います。
それにしても不思議ですよね。あれだけ「無理やり学習素材を作っていた」ことを考えると、拡大以外なんの加工もせずにkohya_ssに放り込んで、ものの数分で出来たLoRAが、十分に使えそうなんですから。
というわけで、ここからは、いくつかのシチュエーションで生成してみたいと思います。
山登り

パラメータ等は前回と同様で、epoch 160 / weight 0.9 です。
正面向きの、たった1枚の画像から、これだけ横向きの画像が生成できるんですね。もちろん、プロンプト次第で完全な後ろ向きの姿もできますが、さすがに同一人物かどうかは判断がつきません。。

こちらは逆向き。epoch 180 / weight 0.9 です。
若干、笑顔が増していて歯が見えているので雰囲気が違って見えます。雰囲気が違うだけのか、原画に似てないのか。
このあたりが面白いと思いますよね。学習素材に無いところはベースモデルが補っているわけですが、そもそもが生成AIで作成した人物画像なので、何をもって似てる・似てないというのか、と。
ここでは2枚をピックアップしましたが、やっぱり、「これは明らかに別人だ」と思うものも多数出ますし、「これは化け物だ」という人の顔とは思えないようなものも生成されます(←特に全身画像などで顔が小さいとき)。
その没画像が多々生成されるのもローカル環境なら許せるのかな、と思います。電気代と生成時間はかかってますけどね。それだけですから。
オフィス
プロンプトは、山登りのものをベースに、活気あるオフィスということでアレンジしました。1行目の使用したLoRAとweightはいろいろ変えて生成しています。
<lora:ai_model_sdxl_b1-000180:0.9>, ai_model_sdxl_b1,
young woman, solo, upper body,
three-quarter view,
body turned slightly to the side,
face turned toward camera,
light smile,
operate a computer,
business suit, at lively office,
realistic, natural lighting

プロンプトで示した epoch 180 / weight 0.9 を使用しています。
Seed値をランダム(-1)に設定して、何枚も生成していると、面白いのが出てくるんですよね。

プロンプトが同じなのに、こんな角度から見るんだ…、という画像になっています。
この角度から見るから違って見えるだけなのか、似てないだけなのか…。
ランダムの面白いところです。
最後の1枚
今回の締めくくりの1枚は、アイキャッチにも使っている写真を持っている姿。
ただ、最初にお断りしておきます。持っている写真に写っている画像は合成です。
プロンプトは、こちら。
<lora:ai_model_sdxl_b1-000180:0.9>, ai_model_sdxl_b1,
masterpiece, best quality, realistic, photorealistic,
one woman in a living room, upper body only,
she is holding a small photograph of herself and looking at it,
cozy living room, warm light, quiet nostalgic mood,
soft natural lighting, sofa in background, shallow depth of field,
smiling , detailed hands, detailed face, cinematic composition
主の人物は、かなり高確率で本人らしさが出ます。やっぱり、顔の角度が学習素材から離れれば離れるほど、別人感は増してきますね。それは仕方がないことだと思います。
本来なら、特定の人物のLoRAを作成しようとすれば、いろんな角度からの写真を撮ったり、いろんな表情の写真を撮ったりして、その人らしさを学習するわけですけど、なんせ、たった1枚の生成画像から作り出したLoRAですから、どこかで歪が出てしまいます。
とはいえ、ほぼ加工無しの画像でここまでできた、というのは、私自身が驚いているところです。
「あれ?今までの苦労は何だったの?」と。
でも1枚の画像でLoRAが作れる、というのは、元が「正解のない」生成画像だからこそ成立する話なんだろうな、と思っています。
リアルな人物だと、学習に使用した顔の向きや表情以外では、「なんか違う」になるのかなと思いますね。
最後に種明かしになりますが、このプロンプトで生成された元画像はこちらです。

いや、さすがに違うだろ、という写真だったんで、この画像を、img2imgの、Inpaintで書き換えました。
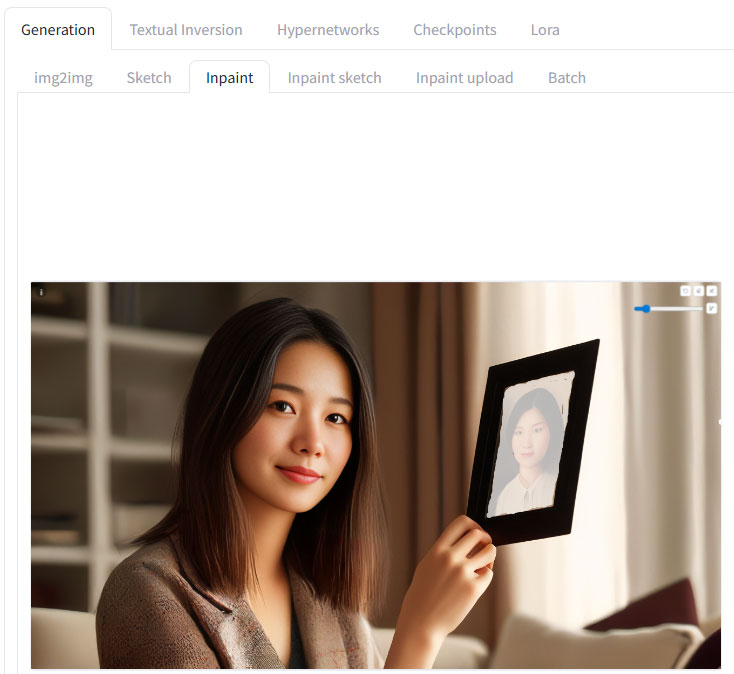
写真の部分にマスクをして、これらのパラメータで画像を生成しています。
Resize mode:Just resize
Mask blur:4
Mask mode:Inpaint masked
Masked content:original
Inpaint area:Only masked
Only masked padding, pixels:32
Sampling method:DPM++ 2M
Schedule type:Karras
Sampling steps:25
CFG Scale:4.5
Denoising strength:0.65
プロンプトが
a small printed portrait photo of the same woman,
the woman in the photo, smiling gently, navy suit and white shirt,
portrait photo, realistic face, natural skin texture,
clear face, looking at camera,
printed photograph, slightly glossy paper,
clear small face, detailed face in photo,
<lora:ai_model_sdxl_b1-000180:2>ai_model_sdxl_b1
Denoising strengthを強めにすると似る度合いが高まるのかな、と思います。
そんなわけで、今回は、生成した1枚の画像から、SDXLのLoRAを作成すると想像していた以上に使えるものが出来た、という内容でした。
Stable Diffusionの環境構築からLoRA作成、SDXLでの検証までの記事一覧は、以下のまとめページに整理しています。
