
VRAM 8GBでの画像生成&LoRA作成 ~ 画像生成AI実験メモ ③

RTX 5070 Ti を搭載した HPのPC、OMEN 35Lを購入して7ヶ月。到着したのが1ヶ月後だったので使用している期間は半年ほどとなりますが、この間、画像生成AIの面白さを味わってきました。

それまでは、5年前に購入した同じくHPのPC、OMEN 25Lで半年ほど Stable Diffusionを使用した画像生成をかじっていたんですが、OMEN 35Lと引き換えに処分したわけではないので、サブ機としてまだまだ頑張れるんじゃないか、と、いろいろと試してみることにしてみました。
本記事に掲載している人物画像は、すべて生成AIにより作成したものであり、特定の実在人物をモデルにしたものではありません。
RTX 2060 SUPERの実力は
もちろん、RTX 5070 Ti と、OMEN 25Lに搭載されている RTX 2060 SUPER との勝負をするつもりは一切ありません。さすがに結果は目に見えてますからね。やってみたいのは、VRAM 8GBでも十分に楽しめる、という結果を出せないかな、というところです。
主だったところを比較してみます。
| 項目 | RTX 5070 Ti | RTX 2060 SUPER |
|---|---|---|
| 世代 | GeForce RTX 50 / Blackwell | GeForce RTX 20 / Turing |
| 登場年月 | 2025年2月 | 2019年7月 |
| VRAM容量 | 16GB GDDR7 | 8GB GDDR6 |
| CUDAコア | 8,960 | 2,176 |
| Tensor Core | 第5世代 | 初代世代 |
| メモリ帯域 | 896GB/s | 448GB/s |
| 消費電力 / TGP | 300W | 175W前後 |
性能を比べちゃいけません。2060 SUPER が勝ってるのは消費電力が小さいというのと、5070 Tiよりも先輩ということくらいなので。。
とはいえ、8GBのVRAMやTensor Core搭載ですから、画像生成用途にもそれなりに実用的といえる世代なのかなと思っています。
まずは環境構築
RTX 2060 SUPERでの Stable Diffusion ( AUTOMATIC1111 WebUI + SD1.5 )の環境構築は、基本的には 5070 Tiのときと同じです。ですので、こちらを見つつ、以下の文章を読んで頂ければ、と思います。
まずは、手順通り、NVIDIAのアプリで「Game Ready ドライバーの最新版」をインストールします。
2026/5/26リリースの Ver. 610.47 となりました。
半年前までStable Diffusionでの画像生成を行っていたPCですので、当然ながら Git や Python3.10 はインストール済み…だと思っていたんですが、
PS E:\AI\automatic1111> python --version
Python 3.11.9となりますね。3.10系の方が安定すると思うので、実行する仮想環境(venv)でPythonのバージョンを指定をする必要がありそうですね。
3.10系が入ってなかったということは、3.11系でも普通に動いていた、ということなんですかね。3.13系では厳しかったのを記憶してますが。。
導入するフォルダで、githubから環境を取得。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.gitstable-diffusion-webui.git の取得はあっという間に終わります。
その後、これ大事です。大事なので、もう一度繰り返しておきます。
cd stable-diffusion-webui
git switch dev
git pull5070Tiのときに dev に切り替えていたのが、なんとなく勝手に 5070 Tiだから必要なんだ、と思ってましたが、そもそもdevブランチじゃなくて本流側でダウンロードをするアプリがなくなってたんですね。。
次いで、Pythonバージョンの件。そのフォルダで、
py -3.10 -m venv venvとして、Pythonのバージョンを3.10に固定して仮想環境の作成を実行。念のため、確認しておきます。まずは、venvをアクティベート。
PS E:\AI\automatic1111\stable-diffusion-webui> .\venv\Scripts\activate.ps1その後で、
(venv) PS E:\AI\automatic1111\stable-diffusion-webui> python --version
Python 3.10.11大丈夫ですね。
SD1.5のベースモデル、v1-5-pruned-emaonly.safetensors を所定の位置に格納して、stable-diffusion-webui内 にある webui-user.bat を叩きます。
初回なのでダウンロードやインストールに時間がかかりますが、ブラウザに Stable Diffusion(A1111) の画面が開きました。
とりあえずは、同じことをやってみましょう。パラメータはさわらずに、プロンプトに、「mountains and lodges」とだけ入力して、オレンジ色の「Generate」ボタンをクリック。

Seed値は-1ですので、当然、生成される画像は違いますが、山とロッジ。まさか、内側が出てくるとは思いませんでしたが。。
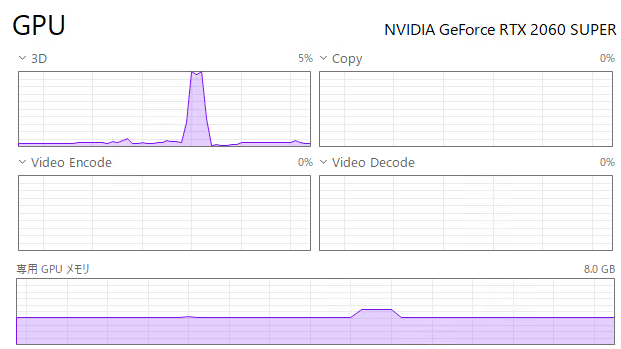
生成時には、きちんとGPUが動作していることも確認できました。
プロンプトで画像生成
続いては、プロンプト(だけ)で意図した画像が生成できるか、という実験です。山小屋が出てきているので、特に問題は無いと思いますから、この記事で行った最終パターンだけで確認してみたいと思います。

ちょっと長いですが、プロンプトとネガティブプロンプトを再掲してみます。
prompt
a young adult japanese woman, portrait photo,
black hair, brown eyes,
simple straight hairstyle with minimal volume,
camera at eye level,
natural makeup,
attentive eyes with a calm, soft gaze,
calm and approachable expression,
slight smile as a natural response,
soft, friendly impression,
subtle jaw definition,
clean transition from jaw to neck,
front-facing or very slight angle, head upright,
soft facial structure, gentle facial proportions,
distinctively east asian facial features,
natural skin texture,
simple casual clothes,
clean but understated appearance,
indoor setting,
soft, slightly uneven natural light
negative prompt
anime, illustration, cartoon, CGI, render, doll-like,
overly generic, stock photo look,
fashion model, runway look,
sharp eyes, upturned eyes, overly defined eye shape,
strong smile, wide smile, teeth visible,
prominent cheekbones, strong jaw structure,
excessive volume on top,
puffy hair on top,
tall hair silhouette,
overly rounded jawline,
heavy jaw
SD1.5での512×512の画像生成ですから、生成中のGPUメモリの使用量も 4.2/8.0 GBという感じで、1枚当たりわずか3秒ほどで、このような画像が生成されます。

横幅を768にして、768×512の画像も生成できます。こちらは、1枚当たり5秒ほどになったでしょうか。
もちろん 5070 Ti より生成時間はかかりますが、十分に実用的な範囲だと思います。
kohya_ssでLoRAを作成
続いてはLoRA導入について、となります。
学習するために使用する環境、kohya_ssの導入手順はこちらを参照ください。

この記事では Blackwell世代の 5070 Ti 向けに、cu128のPyTorchを使用するのでPyTorchのインストールから始めていましたが、そのあたりは、不要っぽいですね。
いきなり setup.bat の実行からで大丈夫です。
が、setup.bat を実行して「pkg_resourcesが見つからない」というエラーが出るくだりは同じですね。同手順を実行して先に進めてください。
再度 setup.bat を実行して、「1. Install kyohya_ss GUI」の「1」を入力して進めるんですが、5070 Ti のときに躓いたところは難なくクリア。
「7. Exit Setup」で抜けた後、
python -c "import pkg_resources; print('OK', pkg_resources.__file__)"を実行すると…。
lion-pytorch 0.0.6
open-clip-torch 2.20.0
pytorch-lightning 1.9.0
pytorch_optimizer 3.5.0
torch 2.7.0+cu128
torchmetrics 1.9.0
torchvision 0.22.0+cu128あれれ? cu128が入ってる。。
cu128までは必要ないと思ってたんですが、問題ないなら最新寄りに、ということなんですかね。5070 Tiでの環境作成も見直さないといけないかも(不要な手順を含んでいるかも)、です。
gui.bat を実行すると、さほど時間をかけずに処理が始まり、
* Running on local URL: http://127.0.0.1:7860と表示されました。
ブラウザから http://127.0.0.1:7860 を開くと kohya_ss の画面となります。
学習素材作成は省略させてもらって、初回のLoRA作成時に使用した学習素材データをそのまま利用することにします。
初期値から変えた項目は同じつもりだったんですが。。
大丈夫かなと思いつつ、Train batch sizeも2としたんですが、総ステップ数が同じなのに、学習に要した時間はわずかに3分7秒。5070Tiのときに生成したファイルのタイムスタンプを確認すると 1つ目(Epoch10)の生成時刻から8つ目(Epoch80)の生成時刻の差分が8分31秒。これはちょっと、5070Ti側の設定を再確認する必要がありますね。初期値と思っていた環境が違っていたのかもしれません。
それはともかく、生成したLoRAの確認。
記事最後のプロンプト・ネガティブプロンプトで生成したのがこちら。

良くも悪くも、安定の構図と顔の傾きですね。。
とはいえ、しっかりとLoRAは生成できているようです。
別のLoRAも作成してみる
シリーズと全く同じ手順を振り返るのも何なんで、

この記事の最後に作製したLoRAを再生成してみたいと思います。ですので、今回も学習素材は既に作成したものを再利用します。
30枚の画像を80回ずつ学習するので、総ステップ数は2400。バッチサイズが2ですので、実動作的には1200ステップですね。
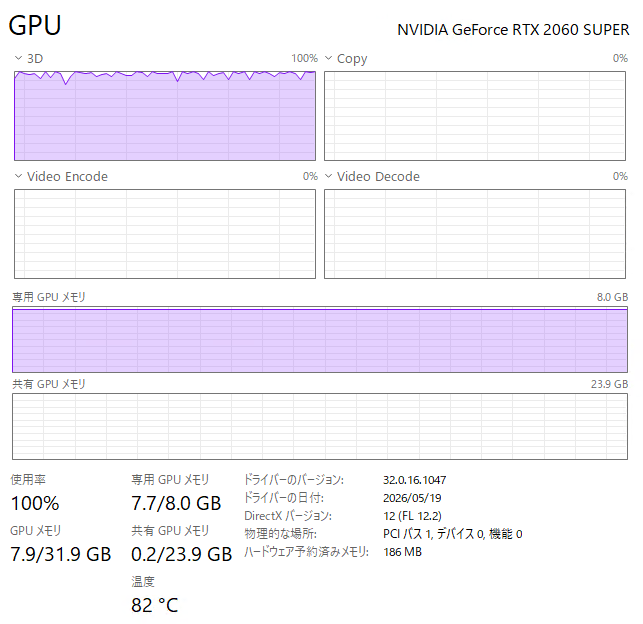
2060 SUPERがフル稼働状態です。82℃にまで上昇してます。ちなみに、GPUメモリが極めてギリギリの7.7GBまで使用していることになっていますが、裏で AUTOMATIC1111 WebUI が起動中で、SD1.5のモデル分を抱えたままになっている状態です。これを開放してやれば余裕が出ます。
逆に、それでメモリオーバーになることも想定していたので、8GBでも案外いけるな、という印象です。
全力疾走した甲斐あって、9分25秒で完了しているのはすごいですね。
このLoRAを使用して、記事中に書いた「指定ポーズへの追随確認」の「腕組み」を epoch20~80(枝番なし)、weight 0.4~1.0(0.2刻み)で生成します。
合計28枚の生成に要した時間は2分39秒。1枚当たり5秒台です。
画像そのものはほぼ同じですので掲載は省略しますが、同じようにLoRAが作成できた、ということですね。
記事最後のオフィスを出すプロンプトで生成した1枚がこちら。

複数生成した中からベストなものを選んだんですが、いい感じになったと思います。
というわけで、SD1.5でのプロンプトによる画像生成、LoRA作成、それにLoRAを使用した画像生成を行いましたが、VRAM 8GB の RTX 2060 SUPER でも十分に、実用的に使用できると感じました。
SDXLではどうなる?
SD1.5だと十分に使えることがわかったので、次にやってみたいのは、SDXLでの画像生成とLoRAの作成ですよね。
というわけで、こちらの記事通り、SDXLのベースモデルを取得します。

その後、SD1.5のときと同じように、プロンプトだけで日本人女性の画像を生成してみたいと思います。
上記のリンクはLoRAを使用することが前提となってますので、SDXLのプロンプトだけで画像生成したときの記事、

こちらの最後に掲出したプロンプトで挑んでみたいと思います。
prompt
a Japanese woman in her late 20s, portrait photo,
natural makeup, light makeup,
gentle smile,
friendly and helpful expression,
calm and trustworthy atmosphere,
wearing a navy blazer and white blouse,
realistic skin texture
ネガティブプロンプトは何も入れてません。
パラメータは、
・Sampler: DPM++ 2M Karras
・Sampling Steps: 35
・CFG: 5.5
・Size: 1024×1024
です。
では、と、モデルを切替え。切替えだけです。生成はしてません。
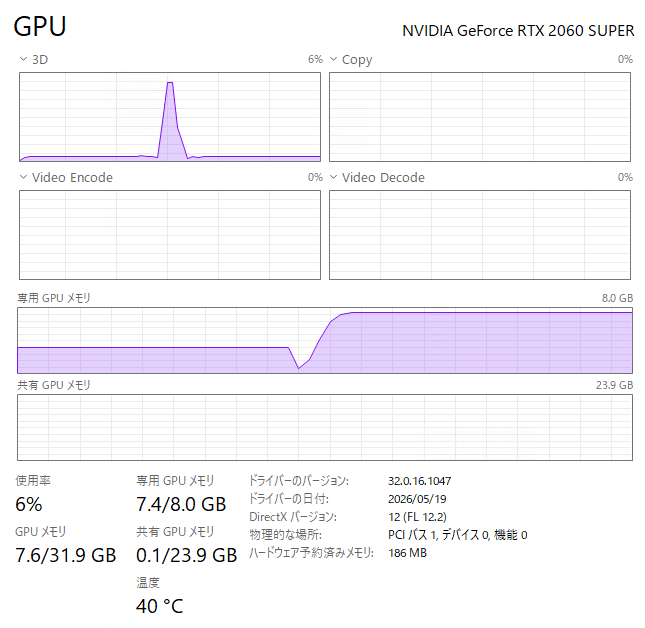
お、おー。。
結構インパクトのある増加になりますね。
でも、まぁ、やってみましょう。
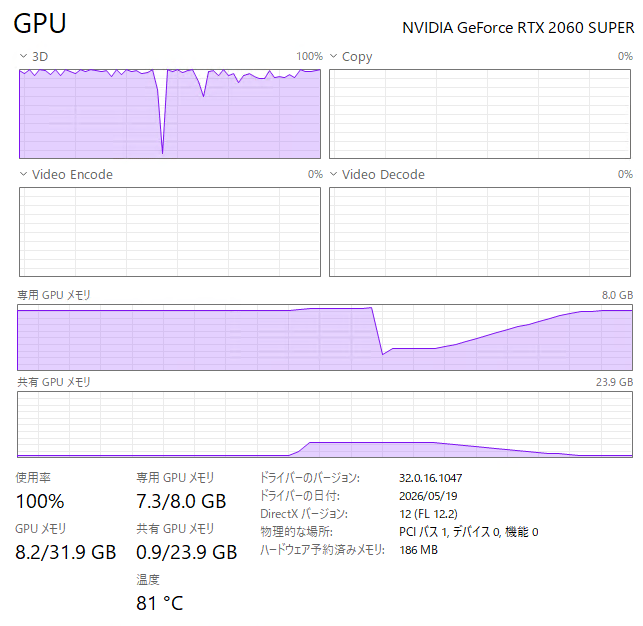
やっぱり、SDXLでの1024×1024サイズの生成は、VRAMあふれが発生しますね。共有GPUメモリが使用されている状況が見えます。共有GPUメモリは、通常のRAMが使用されることになるので、アクセス速度は激遅になります。
10枚を連続して生成したのに要した時間は、10分30秒。1枚当たり平均で1分3秒ですね。SD1.5での512×512が3秒強だったのに比べると恐ろしく遅くなります。
とはいえ、生成された画像そのものは、文句ありません。

穏やかな表情をした20代後半くらいの日本人女性です。
ただ、ちょっと気になったのが、このような表示が出ていること。

fp16演算でNaNが発生しているのでfp32を使用して再計算してますよ、と。
なので、ひょっとしたら、fp16に対応したVAEを使用したら何らかの改善が出来るのかな、と思って、

この記事に書いた sdxl_vae.safetensors をダウンロードして、stable-diffusion-webui / models / VAE に格納したうえで、
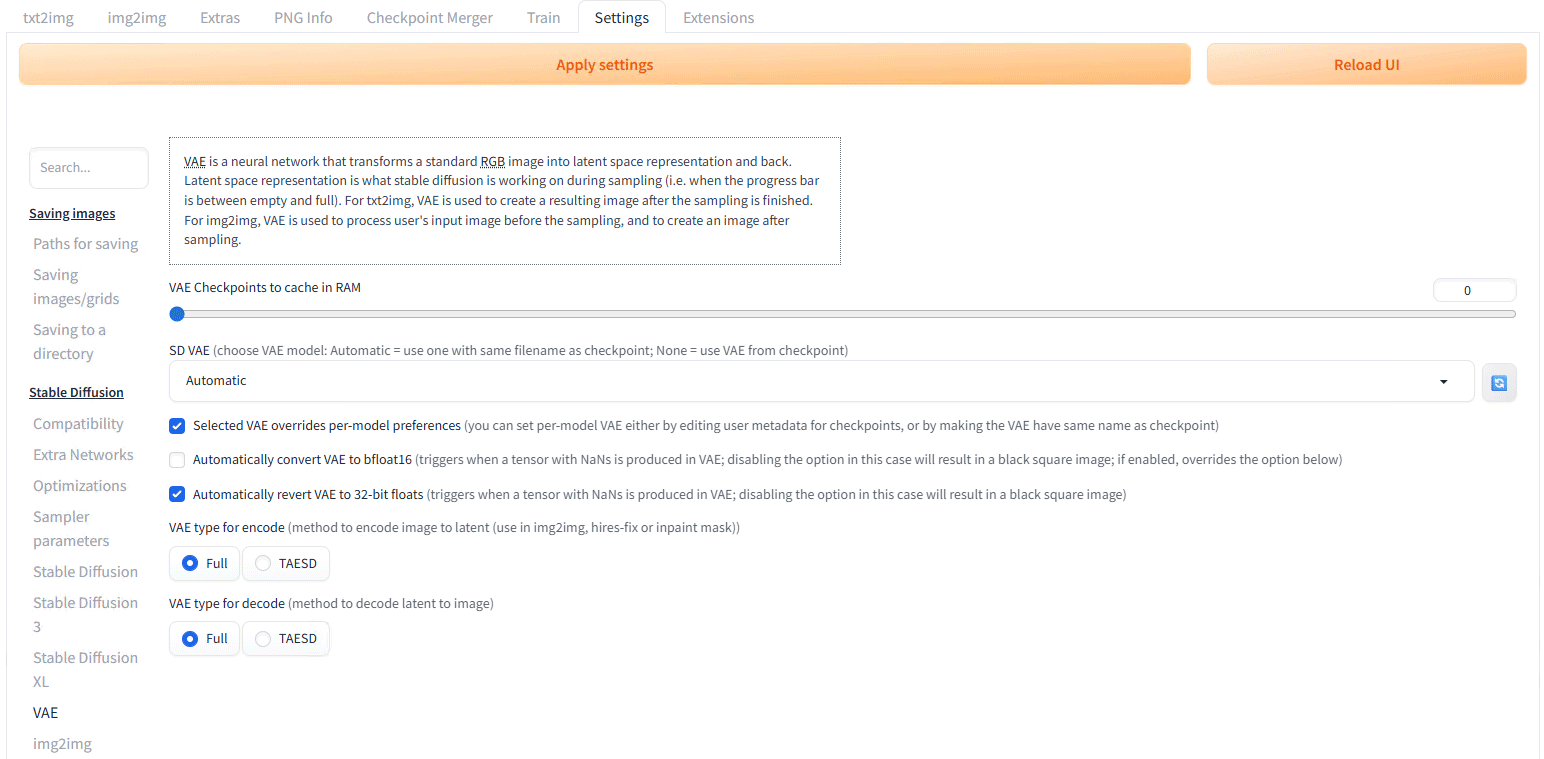
AUTOMATIC1111 WebUI の Settings 画面にある VAEの設定項目でSD VAEのAutomaticを(対応VAEを格納する前は、AutomaticかNoneだけ)sdxl_vae.safetensors に切替え。(VAEファイルを格納した後で、右端のくるくるアイコンをクリックすると一覧に表示されるようになります)

…が。行数を使って書いた割には何の効果も無く。いや、エラーは消えました。確かに。
でも、生成時間は10枚で11分52秒と伸びていて、VRAMの削減には至りませんでした。32bitから16bitに下がるので、なんらか良い影響があるのかな、と期待したんですけどね。生成された画像の方に、目立った変化はありませんでした。
SDXLでの実用サイズは?
1枚で1分かぁ、とちょっとため息をついたところで、「いや、以前はもうちょっと速かったはず」と、何が違うのかを考えていたら、人物画の生成は、縦1024x横768という、縦長のXGAで作成していたんですね。今回は、5070 Tiのときに高速だった1024×1024(SDXLで自然なサイズ)にこだわったからかな、と。
というわけで、同じプロンプト、同じパラメータで、サイズの横幅だけ768にしてみました。
10枚で8分33秒。1枚当たり50秒強ですね。確かに減りはしたんですが。。
しばし首を傾げて当時作成していた画像を「PNG Info」で見てみると、Steps: 20 となってました。確かにそれくらいだったかも。
サンプラーが DPM++ 2M Karras だと、ステップ数は 20~30あたりが実用域ということらしいので、35は過剰だったかもしれません(画質を高めるためには有効です)。ということで、20にして再度10枚。
生成時間は6分5秒。1枚当たり約36秒です。

質感が特に変わったようには見えないですね。
もうちょっと高速化に踏み切るなら、768×768あたりが良いかもしれません。
10枚で4分40秒、1枚当たり28秒となります。

SD1.5と同じ512×512ならもっと速いんじゃない?と思って試すと、確かに、高速化されました。10枚で2分18秒と、1枚14秒ほどと半分ほどになるんですが、SDXLでこのサイズだと、プロンプトを聞かなかったり不自然な顔の画像が生成されたりで、意図した画像が半分にも満たず、お薦めはできないですね。
VRAM8GBでの最適サイズは、「待てる時間」とのトレードオフということでしょうね。
SDXLのLoRAも試してみたい
やっぱりLoRAも試してみたい、ということで、
この時に使用したセットで試してみます。
ひとつだけ違うのが、SDXLベースモデルなので、そのままでは avr_loss=nan となることへの対策として、No half VAE にチェックを入れるのではなく、先ほどダウンロードした sdxl_vae.safetensors を使用することにします。これを適用しての LoRA 作成については、この記事に詳しく記載しています。
で、kohya_ssを使用してのLoRA作成となるのですが、必ず AUTOMATIC1111 WebUI を終了させておいてください。さすがに、SDXLモデルでVRAMがパンパンな状態での学習は無謀です。
その他の設定は、26枚の画像を使用したときと同じように変更して実行。
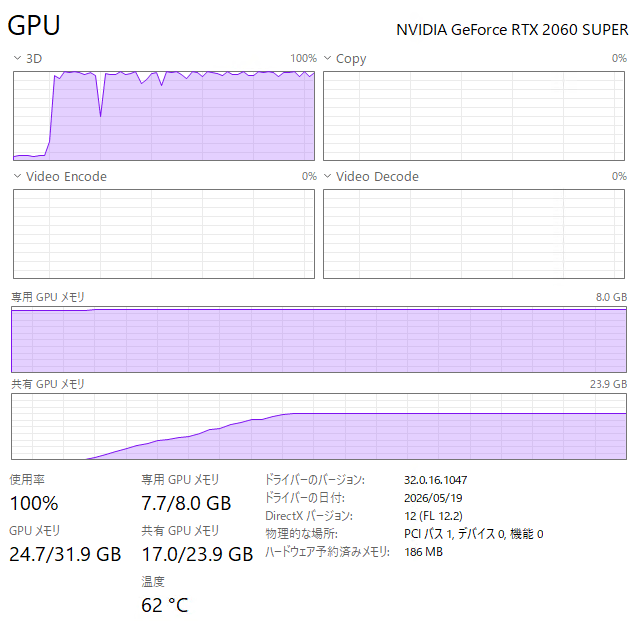
みるみる共有GPUメモリの使用量が上昇して、

終了までの時間が13時間46分に。
いや、さすがに 5070Ti で約40分だった処理に13時間かけるのはどうかしてる気がするので、一旦停止。
設定を見直します。
まずは、バッチサイズが2のままだったので、1に。これは共有メモリの使用量を削減することにはつながったんですが、時間削減にはつながらず。
VRAM使用量に、そこそこ効いたのが、「Advanced」にある「Gradient checkpointing」の項目をONにすること。中間計算結果を必要な時に再計算する方法だそうです。但し、これでも共有メモリの仕様がゼロにはならず、再計算分が増えるためか、想定時間が16時間を超えることに。
共有GPUメモリの使用を回避することが出来たのが、「SDXL Specific Parameters」にある「Cache text encoder outputs」のONです。キャプションから得たテキストエンコーダー出力を事前にキャッシュしておくことで、学習中にテキストエンコーダーをVRAMに常駐するのを防ぐのだそうで、SDXLにはテキストエンコーダーが2つあるため、結構効くようです。
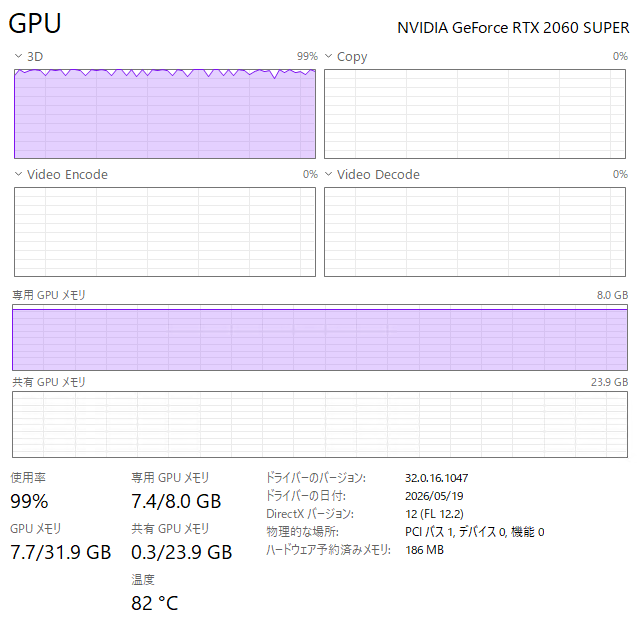
これで、共有GPUメモリ使用がなくなりました。

生成時間もほぼ1時間ほどとなっています。
実際、終了までにかかった時間は、1時間5分6秒でした。もちろん、avr_loss=nan になることなく完遂しています。
ところが、どうも風合いが違うんですね。
使用したプロンプトとパラメータは、同じもの(やや斜めを向いた画像を生成したもの)です。
prompt
<lora:ai_model_sdxl_v1-000040:0.5>, ai_model_sdxl_v1,
young woman, solo, portrait,
three-quarter view,
gentle smile,
plain background,
photo, realistic, natural lighting
negative prompt
(worst quality:2), (low quality:2), (normal quality:2),
lowres, blurry, jpeg artifacts,
extra fingers, mutated hands, bad hands,
bad anatomy, bad proportions,
extra limbs, malformed limbs,
text, watermark, logo
その他のパラメータは、
Sampler:DPM++ 2M Karras
Steps:28
CFG:6
Resolution:1024×1024
Batch:1
Hires.fix:OFF
です。
生成に時間がかかるので、epoch40~80(枝番なし)と weight 0.5~0.9(0.2刻み)を設定して生成しました。

5070Tiでのときは、epoch80(今回の枝番なし)・ weight 0.7で少し斜めを向いた感じになっていたんですが、0.7だと、どれも真正面です。しかも、なんだかアンバランス。
変えた設定項目が影響しているのか、もう一度、5070Tiのときと、どこが違っているのかを精査しておく必要がありそうですね。
とは言っても、最後の山での風景は、こんな画像も出来ました。
prompt
<lora:ai_model_sdxl_v1:0.7> ai_model_sdxl_v1,
young woman, solo, upper body,
three-quarter view,
body turned slightly to the side,
face turned toward camera,
light smile,
outdoor hiking outfit, light jacket, trekking pants, backpack,
standing at a scenic viewpoint,
beautiful mountains and lodges in the background, blue sky,
travel photo, realistic, natural lighting
サイズは、1280×720としています。これで、10枚の生成が14分47秒。1枚当たり約1分30秒ですから、5070Tiのように大量に生成して、ベストなものをピックアップするのは難しいかもしれません。
なぜなら、2ターン、20枚を生成したんですが、使えそうなのは、どちらも2枚ずつ。実質、30分で4枚ですからね。残る16枚はというと、LoRAを作成した元画像の顔に似てる似てないというレベルではなく、人間の顔としての違和感を感じるものが大多数です。
それでも、プロンプトやパラメータを調整していけば、もうちょっと歩留まりは上がるかと思いますし、ローカルPCで(電気代以外の)コストを気にせずに楽しめるのですから、SD1.5はもちろんのこと、SDXLという選択も十分にアリかと思います。
というわけで、VRAM 8GBのGPUでのローカル画像生成を、RTX 2060 SUPERのマシンで実行した、という話でした。GPU世代によって処理速度は異なりますが、VRAM容量による制約という点では、RTX 5060やRTX 4060、RTX 3070など、他の8GB GPUのユーザーにも参考にしていただければと思います。
Stable Diffusionの環境構築からLoRA作成、SDXLでの検証までの記事一覧は、以下のまとめページに整理しています。